L'Altruiste : Le guide des langages Web
Annexe
|
| ||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1111 | 1 * 23 + 1 * 22 + 1 * 21 + 1 * 20 = 8 + 4 + 2 + 1 = 15 |
| 1010 | 1 * 23 + 0 * 22 + 1 * 21 + 0 * 20 = 8 + 0 + 2 + 0 = 10 |
| 1010101010 | 1 * 27 + 0 * 26 + 1 * 25 + 0 * 24 + 1 * 23 + 0 * 22 + 1 * 21 + 0 * 20 = 128 + 0 + 32 + 0 + 8 + 0 + 2 + 0 = 170 |
Pour trouver un nombre binaire ý partir d'un nombre dÈcimal, il faut successivement diviser par deux le nombre dÈcimal puis les quotients rÈsultants jusqu'ý obtenir un zÈro ou un un.
Puis il suffit de lire le nombre binaire en prenant en compte le dernier quotient (1 ou 0) de la division puis effectuer une lecture du bas en haut pour les restes.
| 10 : 2 = 5 | reste 0 | 1010 |
| 5 : 2 = 2 | reste 1 | |
| 2 : 2 = 1 | reste 0 | |
| 15 : 2 = 7 | reste 1 | 1111 |
| 7 : 2 = 3 | reste 1 | |
| 3 : 2 = 1 | reste 1 | |
| 14 : 2 = 7 | reste 0 | 1110 |
| 7 : 2 = 3 | reste 1 | |
| 3 : 2 = 1 | reste 1 | |
| 147 : 2 = 73 | reste 1 | 10010011 |
| 73 : 2 = 36 | reste 1 | |
| 36 : 2 = 18 | reste 0 | |
| 18 : 2 = 9 | reste 0 | |
| 9 : 2 = 4 | reste 1 | |
| 4 : 2 = 2 | reste 0 | |
| 2 : 2 = 1 | reste 0 |
Parfois, il peut Ítre trËs utile de simplifier des expressions boolÈennes de sorte ý devenir plus comprÈhensibles et plus maniables dans un programme.
Lois de distributivitÈsLois de De MorganExp1 OR (Exp2 AND Exp3) = (Exp1 OR Exp2) AND (Exp1 OR Exp3) Exp1 AND (Exp2 OR Exp3) = (Exp1 AND Exp2) OR (Exp1 AND Exp3)
Loi de nÈgationnon(Exp1 AND Exp2) = NOT Exp1 OR NOT Exp2 non(Exp1 OR Exp2) = NOT Exp1 AND NOT Exp2
Loi du milieu exclunon(non Exp1) = Exp1
Loi de contradictionExp1 OR NOT Exp1 = vrai
Lois de simplficationExp1 AND NOT Exp1 = faux
Exp1 AND Exp1 = Exp1 Exp1 AND vrai = Exp1 Exp1 AND faux = faux Exp1 AND (Exp1 OR Exp2) = Exp1 Exp1 OR Exp1 = Exp1 Exp1 OR vrai = vrai Exp1 OR faux = Exp1 Exp1 OR (Exp1 AND Exp2) = Exp1
Les nombres dÈcimaux possËdent une reprÈsentation binaire standardisÈe pour les valeurs de prÈcision simple (32 bits) et double (64 bits) par ANSI/IEEE Standard 754-1985.
Les nombres dÈcimaux simplesLa reprÈsentation binaire des nombres ý virgules flottantes de prÈcision simple requiert un mot de 32 bits, lequel est composÈ d'un bit de signe S, de 8 bits pour l'exposant E et de 23 bits pour la fraction dÈcimale.
S EEEEEEEE FFFFFFFFFFFFFFFFFFFFFFF 0 1EEEEEEE8 9FFFFFFFFFFFFFFFFFFFFFFFF31
La valeur exprimÈe par cette reprÈsentation binaire est dÈterminÈe selon certaines conditions applicables aux parties E, F et S.
| Exposant | Fraction et signe | Valeur |
|---|---|---|
| E=255 | F != nonzero | NaN |
| E=255 | F = 0 ET S = 1 | -Infinity |
| E=255 | F = 0 ET S = 0 | Infinity |
| 0 < E < 255 | (-1)**S * 2 ** (E-127) * (1.F) | |
| E = 0 | F != 0 | (-1)**S * 2 ** (-126) * (0.F) |
| E = 0 | F = 0 | -0 |
| E = 0 | F = 0 | 0 |
La reprÈsentation binaire des nombres ý virgules flottantes de prÈcision simple requiert un mot de 64 bits, lequel est composÈ d'un bit de signe S, de 11 bits pour l'exposant E et de 52 bits pour la fraction dÈcimale.
S EEEEEEEEEEE FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF 0 1EEEEEEEEEE11 12FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF64 |
La valeur exprimÈe par cette reprÈsentation binaire est dÈterminÈe selon certaines conditions applicables aux parties E, F et S
| Exposant | Fraction et signe | Valeur |
|---|---|---|
| E = 2047 | F != 0 | NaN |
| E = 2047 | F = 0 ET S = 1 | -Infinity |
| E = 2047 | F = 0 ET S = 0 | Infinity |
| 0 < E < 2047 | (-1)**S * 2 ** (E-1012) * (1.F) | |
| E = 0 | F != 0 | (-1)**S * 2 ** (-1022) * (0.F) |
| E = 0 | F = 0 | -0 |
| E = 0 | F = 0 | 0 |
| 0 00000000 00000000000000000000000 = | 0 |
|---|---|
| 1 00000000 00000000000000000000000 = | -0 |
| 0 11111111 00000000000000000000000 = | Infinity |
| 1 11111111 00000000000000000000000 = | -Infinity |
| 0 11111111 00000100000000000000000 = | NaN |
| 1 11111111 00100010001001010101010 = | NaN |
| 0 10000000 00000000000000000000000 | |
| = +1 * 2**(128-127) * 1.0 = 2 | |
| 0 10000001 10100000000000000000000 | |
| = +1 * 2**(129-127) * 1.101 = 6.5 | |
| 1 10000001 10100000000000000000000 | |
| = -1 * 2**(129-127) * 1.101 = -6.5 | |
| 0 00000001 00000000000000000000000 | |
| = +1 * 2**(1-127) * 1.0 = 2**(-126) | |
| 0 00000000 10000000000000000000000 | |
| = +1 * 2**(-126) * 0.1 = 2**(-127) | |
| 0 00000000 00000000000000000000001 | |
| = +1 * 2**(-126) * 0.00000000000000000000001 = 2**(-149) | |
Les nombres nÈgatifs possËdent une reprÈsentation binaire spÈcifique afin de les distinguer des nombres positifs.
En fait, les nombres binaires nÈgatifs sont appelÈs nombres signÈs car ils possËdent une longueur fixe et ý leur extrÍme gauche un bit Ègal ý 1.
1000 1001 // est Ègal ý -9 0000 1001 // est Ègal ý +9
En pratique, cette reprÈsentation n'est guËre utilisable puisque l'ordinateur n'est pas capable de gÈrer correctement les opÈrations arithmÈtiques dans ces conditions.
0000 1110 // est Ègal ý 14 + 1000 1001 // est Ègal ý -9 1001 0111 // est Ègal ý -23 0000 0101 // devrait Ítre Ègal ý 5
Devant ce dysfonctionnement patent, il est nÈcessaire de reprÈsenter diffÈremment les nombres binaires nÈgatifs.
0000 1001 // est Ègal ý 9 1111 1111 // complÈment ý 1 0000 1001 1111 0110 0000 0001 // ajout de 1 1111 0111 // est Ègal ý -9 1111 0111 0000 1001 // ajout de 9 0000 0000 //est bien Ègal ý 0
En premier lieu, le nombre est complÈmentÈ ý 1 puis la valeur binaire 1 est ajoutÈe pour donner finalement une reprÈsentation binaire exploitable du nombre nÈgatif correspondant.
ReprÈsentation des nombres binaires nÈgatifs0000 1110 // est Ègal ý 14 + 1111 0111 // est Ègal ý -9 0000 0101 // est Ègal ý 5
| Nombre nÈgatif | |
|---|---|
| Code binaire | Nombre dÈcimal |
| 1111 1111 | -1 |
| 1111 1110 | -2 |
| 1111 1101 | -3 |
| 1111 1100 | -4 |
| 1111 1011 | -5 |
| 1111 1010 | -6 |
| 1111 1001 | -7 |
| 1111 1000 | -8 |
| 1111 0111 | -9 |
| 1111 0110 | -10 |
| 1111 0101 | -11 |
| 1111 0100 | -12 |
| 1111 0011 | -13 |
| 1111 0010 | -14 |
| 1111 0001 | -15 |
| 1111 0000 | -16 |
Le tableau ci-dessous fournit la liste des diffÈrents types d'encodage et leur nom utilisable sur Internet et leur disponibilitÈ sur Mac OS.
| Les langages d'encodage | ||
|---|---|---|
| Universels | Europe de l'Ouest | |
| Europe centrale | Arabes | |
| Chinois | Cyrilliques | |
| Grecs | HÈbraÔques | |
| Indiens | Japonais | |
| CorÈens | ThaÔs | |
| Turcs | Vietnamiens | |
| symboliques | ||
| Les langages | ||
|---|---|---|
| Type d'encodage | Nom commun sur Internet | Information |
| Unicode 2.0 (16 bit) | UTF-16 | |
| Unicode 2.0 UTF-8 | UTF-8 | |
| Unicode 2.0 UTF-7 | UTF-7 | |
| Unicode 1.1 (16-bit) | UNICODE 1-1 | |
| Unicode 1.1 UTF-8 | ||
| Unicode 1.1 UTF-7 | UNICODE-1-1-UTF-7 | |
| ASCII | US-ASCII | |
| ISO 8859-1 (Latin-1) | ISO-8859-1, latin1 | |
| ISO 8859-3 (Latin 3) | ISO-8859-3 , latin3 | |
| ISO-8859-15 (Latin 9) | ISO-8859-15, latin9 | Latin-1 avec le signe EURO et les lettres cp1252 |
| CP 1252 (Windows Latin-1) | windows-1252, cp1252 | ISO 8859-1, plus des ajouts dans la zone C1 |
| CP 437 (DOS Latin-US) |
cp437 | |
| CP 850 (DOS Latin-1) | cp850 | |
| Mac OS Roman | mac, macintosh, x-mac-roman | |
| Mac OS Icelandic | x-mac-icelandic | FondÈ sur Mac OS Roman |
| Mac OS Latin-1, Mac OS Mail |
x-mac-latin1 (communÈment assimilÈ ý ISO-8859-1) | Mac OS Roman permutÈ pour s'aligner ý 8859-1 |
| NextStep Latin | ||
| CP 037 (EBCDIC-US) | cp037 | ISO 8859-1 avec diffÈrentes dispositions |
| ISO 8859-2 (Latin-2) | ISO-8859-2, latin2 | |
| ISO 8859-4 (Latin-4) | ISO-8859-4, latin4 | |
| CP 1250 (Windows Latin-2) | windows-1250, cp1250 | Partiellement 8859-2, plus des ajouts de C1 |
| CP 1257 (Windows Baltique) | windows-1257,cp1257 | |
| Mac OS Central Roman europÈen |
x-mac-centraleurroman | |
| Mac OS Croatian | x-mac-croatian | FondÈ sur Mac OS Roman |
| Mac OS Romanian | x-mac-romanian | FondÈ sur Mac OS Roman |
| ISO 8859-6 (Latin/Arabe) |
ISO-8859-6, arabe | |
| CP 1256 (Windows Arabe) |
windows-1256, cp1256 | Partiellement basÈ sur 8859-6, plus des ajouts de C1 |
| CP 864 (DOS Arabic) | cp864 | Encode les formes de prÈsentation Arabe |
| Mac OS Arabic | x-mac-arabic | |
| Mac OS Farsi | x-mac-farsi | |
| GB 2312-80 | ||
| EUC-CN | GB2312, X-EUC-CN | ASCII et GB 2312-80 (8-bit) |
| CP 936 (DOS et Windows simplifiÈs) |
Similaire ý GBK | |
| Mac OS Chinois simplifiÈ |
FondÈ sur EUC-CN | |
| ISO 2022-CN ("GB") | ISO-2022-CN | ASCII et GB 2312-80 (7-bit) (voir RFC 1922) |
| HZ | HZ-GB-2312 | ASCII et GB 2312-80 (7-bit) (voir RFC 1842); |
| GBK (extended GB) | EUC-CN et Unihan (8-bit) | |
| CNS 11643 plane 1 | x-cns11643-1 | |
| CNS 11643 plane 2 | x-cns11643-2 | |
| EUC-TW | X-EUC-TW | ASCII et CNS 11643-1992 (8-bit) |
| Big-5 | Big5 | (8-bit) |
| CP 950 (DOS et Windows traditionnel) |
FondÈ sur Big-5 | |
| Mac OS (Chinois traditionnel) |
FondÈ sur Big-5 | |
| CCCII | ||
| EACC | ||
| ISO 8859-5 (Latin/Cyrillique) |
ISO-8859-5, cyrillique | |
| KOI8-R | KOI8-R | Voir RFC 1489 |
| CP 1251 (Windows Cyrillique) |
windows-1251, cp1251 | non fondÈ sur ISO 8859-5 |
| CP 866 (DOS Russe) |
cp866 | |
| Mac OS Cyrillic | x-mac-cyrillic | |
| Mac OS Ukrainian | x-mac-ukrainian | Mac OS Cyrillic avec deux remplacements |
| ISO 8859-7 | ISO-8859-7, grec | |
| ISO 5428 | ISO_5428:1980 | |
| CP 1253 (Windows Grec) |
windows-1253, cp1253 | Quasiment fondÈ sur 8859-7, plus des ajouts de C1 |
| Mac OS Greek | x-mac-greek | |
| Greek CCITT | greek-ccitt | |
| ISO 8859-8 (Latin/HÈbreux) |
ISO-8859-8, hÈbreux | |
| CP 1255 (Windows HÈbreux) |
windows-1255, cp1255 | Principalement basÈ sur 8859-8, plus des ajouts C1 |
| Mac OS Hebrew (2 variantes) |
x-mac-hebrew | |
| ISCII-91 | Encodages parallËles pour tous les scripts indiens | |
| Mac OS Gujarati | ||
| Mac OS Devanagari | ||
| Mac OS Gurmukhi | ||
| JIS X0208 | ||
| JIS X0212 | ||
| EUC-JP | EUC-JP, X-EUC-JP | JIS 201, JIS 208 et JIS 212 (8-bit) |
| ISO 2022-JP ("JIS") |
ISO-2022-JP | JIS 201, JIS 208 et JIS 212 (7-bit); RFC 1468 |
| Shift-JIS | Shift_JIS, x-sjis, x-shift-jis | JIS 201 et JIS 208 (8-bit) |
| CP 932 (DOS et Windows) |
FondÈ sur Shift-JIS | |
| Mac OS Japanese | FondÈ sur Shift-JIS | |
| KSC 5601-1987 | ||
| EUC-KR | EUC-KR | ASCII et KSC 5601-87 (8-bit); RFC 1557 |
| CP 949 (DOS et Windows) |
Code Hangul unifiÈ : EUC-KR et Johab | |
| Mac OS Korean | FondÈ sur EUC-KR | |
| ISO 2022-KR ("KSC") |
ISO-2022-KR | ASCII et KSC 5601-87 (7-bit): RFC 1557 |
| KSC 5700 | ||
| TIS 620-2533 | ||
| CP 874 (DOS et Windows) |
cp874 | FondÈ sur TIS 620-2533 |
| Mac OS Thai | x-mac-thai | FondÈ sur TIS 620-2533 |
| ISO 8859-9 (Latin-5) | ISO-8859, latin5 | |
| ISO 8859-3 (Latin-3) | ISO-8859-3 | |
| CP 1254 (Windows Latin-5) |
windows-1254, cp1254 | |
| Mac OS Turkish | x-mac-turkish | FondÈ sur Mac OS Roman |
| VISCII | VISCII | RFC 1456 |
| TCVN-n | ||
| CP 1258 (Windows Vietnamien) |
windows-1258, cp1258 | |
| Adobe Symbol | Adobe-Symbol-Encoding | |
| Mac OS Symbol | x-mac-symbol | FondÈ sur Adobe Symbol |
| Mac OS dingbats | x-mac-dingbats | FondÈ sur Adobe Zapf Dingbats |
| CaractËres | Codes numÈriques | RÈfÈrences d'entitÈs | Descriptions |
|---|---|---|---|
|   | | Espace | |
| ! | ! | ! | Point d'exclamation |
| " | " | " | Marque de citation |
| # | # | # | DiËse |
| $ | $ | $ | Dollar |
| % | % | % | Pour-cent |
| & | & | & | Et commercial (esperluette) |
| ` | ' | ' | Apostrophe |
| ( | ( | ( | ParenthËse de Gauche |
| ) | ) | ) | ParenthËse de Droite |
| * | * | * | AstÈrisque |
| + | + | + | Plus |
| , | , | , | Virgule |
| - | - | ‐ | Tiret (signe moins) |
| . | . | . | Point |
| / | / | / | Barre de fraction (slash) |
| 0 | 0 | Chiffre zÈro | |
| 1 | 1 | Chiffre un | |
| 2 | 2 | Chiffre deux | |
| 3 | 3 | Chiffre trois | |
| 4 | 4 | Chiffre quatre | |
| 5 | 5 | Chiffre cinq | |
| 6 | 6 | Chiffre six | |
| 7 | 7 | Chiffre sept | |
| 8 | 8 | Chiffre huit | |
| 9 | 9 | Chiffre neuf | |
| : | : | : | Deux Points |
| ; | ; | ; | Point-virgule |
| < | < | < | InfÈrieur |
| = | = | = | Egal |
| > | > | > | SupÈrieur |
| ? | ? | ? | Point d'interrogation |
| @ | @ | @ | Arobase |
| a | A | A, Majuscule | |
| b | B | B, Majuscule | |
| C | C | C, Majuscule | |
| D | D | D, Majuscule | |
| E | E | E, Majuscule | |
| F | F | F, Majuscule | |
| G | G | G, Majuscule | |
| H | H | H, Majuscule | |
| i | I | I, Majuscule | |
| J | J | J, Majuscule | |
| K | K | K, Majuscule | |
| L | L | L, Majuscule | |
| M | M | M, Majuscule | |
| N | N | N, Majuscule | |
| O | O | O, Majuscule | |
| p | P | P, Majuscule | |
| q | Q | Q, Majuscule | |
| R | R | R, Majuscule | |
| S | S | S, Majuscule | |
| T | T | T, Majuscule | |
| u | U | U, Majuscule | |
| V | V | V, Majuscule | |
| W | W | W, Majuscule | |
| X | X | X, Majuscule | |
| Y | Y | Y, Majuscule | |
| Z | Z | Z, Majuscule | |
| [ | [ | Crochet Gauche | |
| \ | \ | barre oblique inversÈe (Antislash) | |
| ] | ] | Crochet de droite | |
| ^ | ^ | Accent circonflexe | |
| _ | _ | SoulignÈ | |
| ` | ` | Accent grave | |
| a | a | a, Minuscule | |
| b | b | b, Minuscule | |
| c | c | c, Minuscule | |
| d | d | d, Minuscule | |
| e | e | e, Minuscule | |
| f | f | f, Minuscule | |
| g | g | g, Minuscule | |
| h | h | h, Minuscule | |
| i | i | i, Minuscule | |
| j | j | j, Minuscule | |
| k | k | k, Minuscule | |
| l | l | l, Minuscule | |
| m | m | m, Minuscule | |
| n | n | n, Minuscule | |
| o | o | o, Minuscule | |
| p | p | p, Minuscule | |
| q | q | q, Minuscule | |
| r | r | r, Minuscule | |
| s | s | s, Minuscule | |
| t | t | t, Minuscule | |
| u | u | u, Minuscule | |
| v | v | v, Minuscule | |
| w | w | w, Minuscule | |
| x | x | x, Minuscule | |
| y | y | y, Minuscule | |
| z | z | z, Minuscule | |
| { | { | Accolade de Gauche | |
| | | | | Verticale de barre | |
| } | } | Accolade de Droite | |
| ~ | ~ | Tilde | |
|  ‰ ™ | InutilisÈ | ||
| ™ | ™ | ™ | Signe Marque enregistrÈe |
| š ý Ÿ | ¡ | InutilisÈ | |
|   | | Espace insÈcable | |
| ° | ¡ | ¡ | Exclamation inversÈe |
| ¢ | ¢ | ¢ | Cent (monnaie USA) |
| £ | £ | £ | Livre sterling |
| § | ¤ | ¤ | Symbole monÈtaire gÈnÈral |
| • | ¥ | ¥ | Yens |
| | | ¦ | ¦ ou &brkbar; |
Barre verticale brisÈe |
| ß | § | § | Section |
| ® | ¨ | ¨ ou ¨ |
TrÈma |
| © | © | © | Droit d'auteur |
| ™ | ª | ª | Ordinal fÈminin |
| ´ | « | « | Guillemet franÁais ouvrant gauche |
| ¨ | ¬ | ¬ | Symbole "not" (opposÈ de) |
| - | ­ | ­ | Tiret de cÈsure |
| Æ | ® | ® | Marque dÈposÈe |
| Ø | ¯ | ¯ ou &hibar; |
Macron |
| ∞ | ° | ° | DegrÈ |
| ± | ± | ± | Plus ou moins |
| 2 | ² | ² | Exposant 2 |
| 3 | ³ | ³ | Exposant 3 |
| ¥ | ´ | ´ | Accent aigu |
| µ | µ | µ | Lettre grecque "mu" |
| ∂ | ¶ | ¶ | Paragraphe |
| ∑ | · | · | Point mÈdian |
| ¸ | ¸ | ¸ | CÈdille |
| 1 | ¹ | ¹ | Exposant 1 |
| ∫ | º | º | Ordinal masculin |
| ª | » | » | Guillemet franÁais fermant droit |
| º | ¼ | ¼ | Fraction un quart |
| Ω | ½ | ½ | Fraction un demi |
| æ | ¾ | ¾ | Fraction trois-quarts |
| ø | ¿ | ¿ | Point d'interrogation inversÈ |
| ¿ | À | À | A, accent grave |
| ¡ | Á | Á | A, accent aigu |
| ¬ | Â | Â | A, accent circonflexe |
| √ | Ã | Ã | A, tilde |
| ƒ | Ä | Ä | A, trÈma |
| ≈ | Å | Å | A, anneau |
| ∆ | Æ | Æ | E dans la (ligature) |
| « | Ç | Ç | C, cÈdille |
| » | È | È | E, accent grave |
| … | É | É | E, accent aigu |
| Ê | Ê | E, accent circonflexe | |
| À | Ë | Ë | E, trÈma |
| Ã | Ì | Ì | I, accent grave |
| Õ | Í | Í | I, accent aigu |
| Œ | Î | Î | I, accent circonflexe |
| œ | Ï | Ï | I, trÈma |
| – | Ð | Ð ou Đ |
Eth majuscule |
| — | Ñ | Ñ | N, tilde |
| “ | Ò | Ò | O, accent grave |
| ” | Ó | Ó | O, accent aigu |
| ‘ | Ô | Ô | O, accent circonflexe |
| ’ | Õ | Õ | O, tilde |
| ÷ | Ö | Ö | O, trÈma |
| x | × | × | Signe "multipliÈ" |
| ÿ | Ø | Ø | O, barrÈ |
| Ÿ | Ù | Ù | U, accent grave |
| ⁄ | Ú | Ú | U, accent aigu |
| € | Û | Û | U, accent circonflexe |
| Ð | Ü | Ü | U, trÈma |
| ð | Ý | Ý | Y, accent aigu |
| Þ | Þ | Þ | Thorn majuscule |
| þ | ß | ß | Ligature de szet |
| ý | à | à | a, accent grave |
| · | á | á | a, accent aigu |
| ‚ | â | â | a, accent circonflexe |
| „ | ã | ã | a, tilde |
| ‰ | ä | ä | a, trÈma |
| Â | å | å | a, anneau |
| Ê | æ | æ | e dans l'a |
| Á | ç | ç | c, cÈdille |
| Ë | è | è | e, accent grave |
| È | é | é | e, accent aigu |
| Í | ê | ê | e, accent circonflexe |
| Î | ë | ë | e, trÈma |
| Ï | ì | ì | i, accent grave |
| Ì | í | í | i, accent aigu |
| Ó | î | î | i, accent circonflexe |
| Ô | ï | ï | i, trÈma |
| | ð | ð | eth minuscule |
| Ò | ñ | ñ | n, tilde |
| Ú | ò | ò | o, accent grave |
| Û | ó | ó | o, accent aigu |
| Ù | ô | ô | o, accent circonflexe |
| ı | õ | õ | o, tilde |
| ˆ | ö | ö | o, trÈma |
| ˜ | ÷ | ÷ | Signe "divisÈ par" |
| ¯ | ø | ø | o, barrÈ |
| ˘ | ù | ù | u, accent grave |
| ˙ | ú | ú | u, accent aigu |
| ˚ | û | û | u, accent circonflexe |
| ¸ | ü | ü | u, trÈma |
| ˝ | ý | ý | y, accent aigu |
| ˛ | þ | þ | Thorn minuscule |
| ˇ | ÿ | ÿ | y, trÈma |
| ... | |||
| å | Œ | Œ | E dans l'O |
| ú | œ | œ | e dans l'o |
| ... | |||
| Ä | € | € | Euro |
A - B - C - D - E - F - G - H - I - J - K - L - M -
N - O - P - Q - R - S - T - U - V - W - X - Y - Z
A - B - C - D - E - F - G - H - I - J - K - L - M -
N - O - P - Q - R - S - T - U - V - W - X - Y - Z
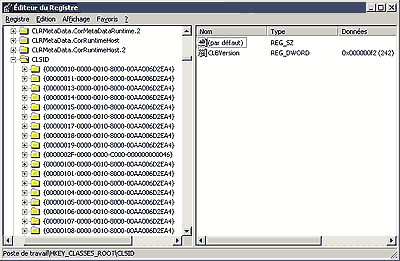
Les identificateurs CLSID (CLasse IDentifier) sont utilisÈs pour appeler des applications Microsoft Windows dans des prorammes Ècrits dans divers langages tels que l'ASP, le PHP ou d'autres.
La liste des identificateurs CLSID prÈsents sur un serveur se trouvent dans le fichier regedit.exe, dans le rÈpertoire HKEY_CLASSES_ROOT classÈs par application.

Une liste complËte classÈe par identificateurs, se trouve Ègalement sous le dossier CLSID du mÍme rÈpertoire.
Les pages de code (CodePages) standards supportÈs par Windows sont citÈes dans le tableau ci-dessous avec le ou les jeux de caractËres et les langues correspondants.
A - B - C - D - E - F - G - H - I - J - K - L - M -
N - O - P - Q - R - S - T - U - V - W - X - Y - Z
Les entÍtes des messages Internet sont normalisÈs par les RFC (Requests For Comments) 822, 2045, 2046, 2047, 2048, 2049 relatif au extensions polyvalentes des messages internet (MIME : Multipurpose Internet Mail Extensions).
| Les champs d'entÍte |
|---|
| From: expediteur@email.com [, ...] CRLF |
| reprÈsente la liste des auteurs du courrier. |
| Sender: expediteur@email.com CRLF |
| reprÈsente l'adresse de l'expÈditeur du courrier. |
| Reply-To: adresse_reponse@email.com [, ...] CRLF |
| reprÈsente l'adresse de rÈponse au courrier Èlectronique. |
| To: destinataire@email.com [, ...] CRLF |
| reprÈsente la liste d'adresses des destinataires du courrier. |
| Cc: destinataire_copie@email.com [, ...] CRLF |
| reprÈsente la liste des destinataires d'une copie du courrier. |
| Bcc: destinataire_copie@email.com [, ...] CRLF |
| reprÈsente les destinataires non-visible d'une copie du courrier. |
| Message-ID: code_message CRLF |
| reprÈsente un code unique d'identification du courrier. |
| In-Reply-To: message_id [, ...] CRLF |
| est utilisÈ pour identifier le (ou les) courriers pour lequel il en est un nouveau. |
| References: message_id CRLF |
| est utilisÈ pour identifier le fil de la conversation. |
| Subject: [Re:] Sujet... CRLF |
| reprÈsente le sujet du courrier Èlectronique avec optionnellement le suffixe Re: pour une rÈponse. |
| Comments: Commentaire... CRLF |
| reprÈsente un commentaire ý propos du courrier. |
| Keywords: Mot-clÈ [, ...] CRLF |
| reprÈsente des mots-clÈs relatifs au courrier. |
| Date: date CRLF |
| reprÈsente des mots-clÈs relatifs au courrier. |
| MIME-Version: 1.0 CRLF |
| reprÈsente la version MIME du courrier. |
| Content-Type: type/sous-type; {charset = encodage} | {boundary = dÈlimiteur} CRLF |
| reprÈsente le type et le sous-type (text/plain, image/jpeg, audio/basic, application/postscript, etc.) et l'encodage (US-ASCII ou ISO-8859-X) du contenu d'un courrier. Si le couple type/sous-type possËde la valeur multipart/mixed ou multipart/alternative, l'attribut boundary permet de dÈlimiter les parties encodÈes diffÈremment par une chaÓne de caractËres spÈciale. |
| Content-transfer-encoding: 7bit | 8bit | binary | quoted-printable | base64 CRLF |
| dÈfinit un mÈcanisme d'encodage du contenu d'un courrier. |
| Content-ID: message_id CRLF |
| reprÈsente une rÈfÈrence ý un contenu d'un autre courrier. |
| Content-Description: texte... CRLF |
| reprÈsente une information descriptive ý propos du contenu d'un courrier. |
From: Jacques Crenca <j_c@domaine.net> To: Jean Jean <jean2@dom.com> Reply-To: "Jacques Crenca" <message@domaine.net> Subject: Re: Bonjour Date: Mon, 25 Mar 2002 09:18:52 -0200 Message-ID: <1255388558@domaine.net> In-Reply-To: <20012500365485@domaine.net> References: <20012500365485@domaine.net> MIME-Version: 1.0 Content-Type: text/plain; charset="iso-8859-1" Content-Transfer-Encoding: 7bit
Le second exemple fait appel ý un contenu mixte en assemblant deux messages ý un courrier Èlectronique.
From: Jacques Crenca <j_c@domaine.net> To: Jean Jean <jean2@dom.com> Bcc: Direction <pdg@domaine.net> Date: Mon, 25 Mar 2002 09:18:52 -0200 Subject: Critique du rapport n∞10254365 MIME-Version: 1.0 Message-ID: <1255388558@domaine.net> Content-Type: multipart/mixed; boundary="/-----10254365-----/" Content-ID: <id53464631236546@site.com> --/-----10254365-----/ PremiËre partie du message... --/-----10254365-----/ Content-Type: multipart/digest; boundary="/-----suite du courrier-----/" --/-----suite du courrier-----/ From: Emile Ntamack <emile@domaine.net> Date: Mon, 25 Mar 2002 09:18:52 -0200 Subject: Remarque d'un interlocuteur Seconde partie du message... --/-----suite du courrier-----/ From: Jean-Pierre Rives <jp.rives@domaine.net> Date: Mon, 25 Mar 2002 09:18:52 -0200 Subject: Remarque d'une autre personne TroisiËme partie du message... --/-----suite du courrier-----/ --/-----10254365-----/--
Un message l'attribut content-type Ègal ý multipart/alternative possËde plusieurs parties proposant un contenu identique mais accessible par diffÈrent mÈcanisme. Dans l'exemple ci-dessous, un contenu spÈcial est proposÈ selon trois mÈthodes alternatives.
From: Jacques Crenca <j_c@domaine.net>
To: Jean Jean <jean2@dom.com>
Date: Mon, 25 Mar 2002 09:18:52 -0200
Subject: Sujet du courrier
MIME-Version: 1.0
Message-ID: <123486709786768@domaine.net>
Content-Type: multipart/alternative; boundary=216878686686346458
Content-ID: <id53464631236546@site.com>
--216878686686346458
Content-Type: message/external-body; name="fichier.ps";
site="laltruiste.com"; mode="image";
access-type=ANON-FTP; directory="fichier/rapport";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID: <id216878686686346458@laltruiste.com>
--216878686686346458
Content-Type: message/external-body; access-type=local-file;
name="/doc/sujet/fichier.ps";
site="laltruiste.com";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID: <id216878686686346458@laltruiste.com>
--216878686686346458
Content-Type: message/external-body;
access-type=mail-server
server="laltruiste@server.net";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID: <id216878686686346458@laltruiste.com>
get fichier.rtf
--216878686686346458--Il existe diffÈrents modes permettant d'affecter des droits d'accËs aux fichiers ou aux rÈpertoires.
Les droits d'accËs peuvent se faire en lecture (r : read), en Ècriture (w : write) et en exÈcution (x : execute) ou bien en une quelconque combinaison de ces trois derniers.
droits d'accËs : rwx r-x r-- Ègale ý 7 5 4
Les permissions peuvent Ítre accordÈes diffÈremment ý trois types d'utilisateurs : les propriÈtaires, les utilisateurs faisant partis d'un groupe et les tous les autres.
Chaque type est reprÈsentÈ par un nombre octal rÈsultant d'une addition des valeurs de bit provenant de chacun de leurs attributs.
Valeurs des attributs| Attribut | Action | Valeur |
|---|---|---|
| r | Aucun | 0 |
| x | eXecute | 1 |
| w | Write | 2 |
| r | Read | 4 |
| Type | Attributs | Valeur |
|---|---|---|
| PropriÈtaire | rwx | 7 |
| Groupe | rwx | 7 |
| Autres | rwx | 7 |
| Valeur | Attributs | Description |
|---|---|---|
| 7 | rwx | procure des droits en lecture, Ècriture et en exÈcution. |
| 6 | rw- | procure des droits en lecture et en Ècriture. |
| 5 | r-x | procure des droits en lecture et en exÈcution. |
| 4 | r-- | procure des droits en lecture seule. |
| 3 | -wx | procure des droits en Ècriture et en exÈcution. |
| 2 | -w- | procure des droits en Ècriture seule. |
| 1 | --x | procure des droits en exÈcution seule. |
| 0 | --- | Aucune permission n'est accordÈe. |
- entier : -limite_systËme, -124, -45, -2, 0, 14, 78, 325, limite_systËme.
- rÈel : -limite_systËme, -43E+541, -15.62, -0.08502, 0.0, 25.36, 9778.03, 759E-95, limite_systËme.
- caractËre : caractËres Unicode : [a-zA-Z0-9] et n'importe quels caractËres accentuÈs (È, ý, ˆ, etc..) ou spÈciaux ($, #, ?, etc..).
- chaÓne : n'importe quelle suite de caractËres "\tUne brebis ÈgarÈe dans la forÍt\n".
- boolÈen : vrai (true : 1) ou faux (false : 0)
- ÈnumÈrÈ : reprÈsente une collection de constantes ÈnumÈrÈes possibles pour une variable.
# CrÈation # type mois : chaÓne : ("janvier","fÈvrier","mars", "avril","mai","juin", "juillet","ao˚t","septembre", "octobre","novembre","dÈcembre",); type num_mois : entier : (1,2,3,4,5,6,7,8,9,10,11,12); - intervalle : reprÈsente un intervalle de valeur possible pour une variable.
# CrÈation # type num_mois : entier : 1..12; type alphabet : caractËre : 'A'..'Z'; type ÈtÈ : mois : "juillet".."septembre";
Les constantes# CrÈation # var identificateur : type; var identificateur : type := valeur_initialisatrice; var i : entier; var j : entier := 0; # Affectation # variable := valeur; phrase := "Une chaÓne de caractËres...";
Les expressions# CrÈation # const IDENTIFICATEUR : type := valeur_constante; const PI : rÈel := 3.14;
Les opÈrateurs arithmÈtiquesvariable : type := expression; nom : chaÓne := "Jean-Pierre" + " " + "RODERER"; surface : rÈel := PI * Rayon ** 2; reussir : boolÈen := vrai et faux ou vrai et non faux;
- + (unaire), - (unaire),
- ** (puissance),
- *, /, div (division d'entier), modulo,
- + (binaire), - (binaire).
Les opÈrateurs boolÈensvar resultat : rÈel := 4 * -5 / -2 + 20 - 5 ** 3 / 10; resultat := ((((4 * (-5)) / (-2)) + 20) - ((5 ** 3) / 10)); resultat := (((-20 / -2) + 20) - (125 / 10)); resultat := 30 - 12.5; resultat := 17.5;
- non
- et
- ou
Les opÈrateurs de comparaisonsnon Exp1 et Exp2 ou Exp3 et non Exp4 ou Exp5 ((((non Exp1) et Exp2) ou (Exp3 et (non Exp4))) ou Exp5)
- = : ÈgalitÈ,
- <> : diffÈrence,
- >= : supÈrieur ou Ègal,
- <= : infÈrieur ou Ègal,
- > : supÈrieur,
- < : infÈrieur.
variable : boolÈen := expression_comparative; rÈussite : boolÈen := i < 10; rÈussite : boolÈen := (i < 10) et (j <> 0); L'opÈrateur de concatÈnation var resultat : chaÓne := chaÓne + chaÓne2 + caractËre + ... + chaÓneN; resultat : chaÓne := "Bonjour " + 'ý' + " tous"; resultat := "Bonjour ý tous";
Les opÈrateurs sont associatifs ý gauche hormis l'opÈrateur de puissance **.
La mise entre paranthËses d'une expression contraint ý une Èvaluation prioritaire de cette derniËre.
Les procÈdures# CrÈation #
proc identificateur[([val param_val: type,...,param_valN: type][;
valres param_val_res: type,...,param_val_resN: type][;
res param_res: type,...,param_rÈsN: type])];
[variable_locale : type := valeur;
...
variable_localeN : type := valeur;]
dÈbut
Instructions...
fproc
proc compteur;
var cpt : entier := 0;
i : entier;
dÈbut
pour i := 0 jusqu'ý 10 faire
cpt := cpt + 1;
Ècrire(i, " ", cpt);
fpour;
fproc
proc tri(val nb : entier; valres un_tableau :
tableau[1..MAX]; res reussie : boolean)# CrÈation #
fonction identificateur([paramËtre: type,...,paramËtreN: type]): type;
[variable_locale : type := valeur;
...
variable_localeN : type := valeur;]
dÈbut
Instructions...
rÈsultat valeur;
ffonction
fonction aire_cercle(diamËtre : rÈel) : rÈel;
var PI : rÈel := 3.14;
dÈbut
aire : rÈel := (PI * (diamËtre ** 2)) / 2;
resultat aire;
ffonction
# Appel de fonction #
variable : type_fonction :=
identificateur_fonction([argument,..., argumentN]);
surface : rÈel := aire_cercle(15);# CrÈation #
type identificateur : struct
variable : type,
...,
variableN : type
fstruct;
...
identificateurN struct
variable : type,
...,
variableN : type
fstruct;
type personnel : struct
identifiant : entier,
nom, prÈnom : chaÓne,
date_naissance : chaÓne(10),
adresse : chaÓne,
code_postal : entier,
ville : chaÓne,
pays : chaÓne,
telephone : entier
fstruct;
sociÈtÈ : struct
num_siret : entier,
nom : chaÓne,
dirigeant : personnel,
nb_personnel : entier
fstruct;
# DÈclaration de variable structure #
var nom_variable : identificateur_structure;
var dirigeant : personnel;
var entreprise : sociÈtÈ;
# Affectation #
identificateur_structure.nom_champs := valeur;
entreprise.dirigeant.nom := "MAGNARD";
entreprise.nom := "ALAPAGE";
entreprise.num_siret := 41426553800010;
# Lecture #
variable : type_champs := identificateur_structure.nom_champs;
pdg : chaÓne := entreprise.dirigeant.nom
+ " " + entreprise.dirigeant.prÈnom
# Utilisation avec avec #
avec identificateur_structure faire
nom_champs := valeur;
variable : type_champs := nom_champs;
favec;
avec entreprise faire
nom := "ALAPAGE";
dirigeant.pays := "France";
avec dirigeant faire
nom := "MAGNARD";
prÈnom := "Patrice";
favec;
favec;# CrÈation #
identificateur : tableau[dÈbut..fin{, ..., dÈbutN..finN}] de type
un_tableau : tableau[1..10,1..10] de entier;
#CrÈation d'un tableau bidimensionnel de 100 cellules#
# Affectation #
tableau[index{, indexN}] := valeur;
un_tableau[1,1] := 12;
# Lecture #
tableau[index{, indexN}] := valeur;
type_tableau : variable := un_tableau[1,1] := 12;Ècrire(valeur);
Ècrire("Notions d'algorithme");si expression_boolÈenne
alors instructions...;
[sinon si seconde_expression_boolÈenne
alors instructions...;]
[...]
[sinon si NiËme_expression_boolÈenne
alors instructions...;]
[sinon Instructions...;]
fsi
si variable < 10 alors
Ècrire("La variable est supÈrieure ý 10 :", variable);
sinon si variable > 10 alors
Ècrire("La variable est infÈrieure ý 10 :", variable););
sinon si variable = 10 alors
Ècrire("La variable est Ègale ý 10 :", variable););
fsichoix
expression_boolÈenne -> cas
Instructions...;
fcas
...
expression_boolÈenneN -> cas
Instructions...;
fcas
fchoix;
choix
mois = "janvier"
ou mois = "fÈvrier"
ou mois = "mars" -> cas;
Ècrire("Nous sommes dans la saison hivernale.");
fcas
mois = "avril"
ou mois = "mai"
ou mois = "juin" -> cas;
Ècrire("Nous sommes dans la saison du printaniËre.");
fcas
mois = "juillet"
ou mois = "ao˚t"
ou mois = "septembre" -> cas;
Ècrire("Nous sommes dans la saison estivale.");
fcas
mois = "octobre"
ou mois = "novembre"
ou mois = "dÈcembre" -> cas;
Ècrire("Nous sommes dans la saison automnale.");
fcas
fchoix;rÈpÈter
Instructions...
jusqu'ý expression_boolÈenne
i : entier := 0;
rÈpÈter
Ècrire("Contenu cellule ", i, " : ", tableau[i], "\n");
i := i + 1;
jusqu'ý i >= tableau.longueur()tant que expression_boolÈenne
Instructions...
fin tant que
i : entier := 0;
tant que i < tableau.longueur()
Ècrire("Contenu cellule ", i, " : ", tableau[i], "\n");
i := i + 1;
fin tant quepour expression_d'initialisation
[1(dÈfaut) | pas expression_d'incrÈmentation]
jusqu'ý expression_finale
faire
Instructions...
fin pour
num : entier := 0;
pour i := 0 pas 2 jusqu'ý 10 faire
num := num + 1;
Ècrire("NumÈro de boucle et valeur de i : ", num, " et ", i);
fin pourlire(variable);
lire(nom);
algorithme
var nom, prÈnom : chaÓne;
dÈbut
Ècrire("Saisissez vos nom et prÈnom ",
"sÈparÈs par une virgule : ");
lire(nom, prÈnom);
Ècrire("Bienvenue dans ce programme ",
prÈnom, " ", nom);
finPrÈcondition et Postcondition# CrÈation # algorithme dÈclaration des objets dÈbut instructions... fin
Une prÈcondition reprÈsente les Ètats initiaux possibles des objets ÈnoncÈs dans un problËme ý rÈsoudre par un algorithme.
Tandis qu'une postcondition reprÈsente les Ètats finaux de ces mÍmes objets.
P : prÈdicat_prÈconditionnel, Q : prÈdicat_postconditionnel # a et b sont des chaÓnes ý comparer lexicographiquement # P: a <> b, Q: c = max(a, b) # signifie que a et b sont strictement diffÈrents et qu'il faut Ècrire un algorithme pour dÈterminer le plus grand d'entre eux. # (c = a et c <> b) ou (c = b et c <> a) algorithme var a, b, c : chaÓne; dÈbut si a > b alors c := a; sinon si b > a alors c := b; fsi; fin P: a >= b Q: c = max(a, b) algorithme var a, b, c : chaÓne; (c = a et c >= b) ou (c = b et c < a) dÈbut si a >= b alors c := a; sinon c := b; fsi; fin P: n > 2, Q: factorielle = f(n) (f = 1 et n <= 2) ou (f = x et n > 2) fonction factorielle(n : entier) : entier; entier : i, f := 1; dÈbut pour i := 2 jusqu'ý n faire f = f * i; fpour resultat f; ffonction
fonction longueur(val chaÓne_source : chaÓne) : entier;
fonction morceau(val var_chaÓne : chaÓne,
pos_dÈbut, pos_fin : entier) : chaÓne;
fonction index(val chaÓne_source,
chaÓne_recherchÈe : chaÓne) : entier;
proc insÈrer(val chaÓne_inseree : chaÓne, position : entier,
valres chaÓne_source : chaÓne);
proc effacer(val pos_dÈbut, pos_fin : entier,
valres chaÓne_source : chaÓne);
# Exemples #
chaÓne_source : chaÓne := "Microsoft ajoutera un outil "
+ "XML ý sa suite Office en 2003.";
taille : entier := longueur(chaÓne_source);
taille := 58;
insÈrer("peut-Ítre ", 19, chaÓne_source);
chaÓne_source : chaÓne := "Microsoft ajoutera peut-Ítre un outil "
+ "XML ý sa suite Office en 2003.";| TABLEAU symbolisant la relation PERSONNEL | |||||
| id | NOM | PRENOM | |||
| L | T | 001357 | LECLERC | Aurore | |
| I | U | 1013056 | CONTINE | Magalie | |
| G | o | p | 1036412 | ASUR | Aurianne |
| N | u | L | 1055848 | ALHEUR | Jean-Christophe |
| E | E | 1103256 | PATTRON | Delphine | |
| S | S | 1123480 | MILLAUD | Marc | |
| C O L O N N E S ou C H A M P S | |||||
fonction compter_ligne(val rel : relation) : entier;
fonction ÈnumÈrer_ligne(val rel : relation) : entier;
fonction ÈnumÈration_terminÈe(val numÈro_ÈnumÈration : entier)
: boolÈen;
proc fermer_ÈnumÈration(val numÈro_ÈnumÈration : entier);
fonction ligne_suivante(val numÈro_ÈnumÈration : entier) : ligne;
proc ajouter_ligne(val rel : relation, ligne : t_ligne,
res ok : boolÈen);
proc supprimer_ligne(val rel : relation, clÈ : t_clÈ,
res ok: boolÈen);
proc modifier_ligne(val rel : relation, ligne : t_ligne,
res ok boolÈen);
proc rechercher_ligne(val rel : relation, clÈ : t_clÈ,
res ligne : t_ligne, trouvÈ : boolÈen);
# Exemples #
var num_lignes : entier := compter_ligne(PERSONNEL);
ajouter_ligne(PERSONNEL, "1032578 MOULET Isabelle", reussi);
rechercher_ligne(PERSONNEL, 1036412, enregistrement, existe);
algorithme
type opÈration : (1, 2, 3);
type tuple : struct
ID : entier,
NOM : chaÓne,
PRENOM : chaÓne
fstruct;
var action : opÈration;
tableau : relation;
ligne : tuple;
ident : entier;
nom, prÈnom : chaÓne;
proc affichage(val rel : relation);
var i : entier := 0;
dÈbut
i := ÈnumÈrer_ligne(rel);
Ècrire("\tID \tNom \tPrÈnom");
tant que non(ÈnumÈration_terminÈe(i))
ligne := tuple_suivant(i);
avec ligne faire
Ècrire("\t", ID, "\t", NOM, "\t", PRENOM);
favec;
fin tant que;
fin
proc modification(rel : relation);
var rÈussi : boolean;
dÈbut
choix
action = 1 -> cas
Ècrire("fournissez les donnÈes (ID, NOM, PRENOM) :");
lire(ident, nom, prÈnom);
avec ligne faire
lire(ID, NOM, PRENOM);
favec;
ajouter_ligne(rel, ligne, rÈussi);
si rÈussi alors Ècrire("Ajout rÈussi !");
sinon Ècrire("Echec de l'ajout !");
fsi
fcas
action = 2 -> cas
Ècrire("fournissez la clÈ de l'enregistrement (ID) :");
lire(ident);
supprimer_ligne(rel, ident, rÈussi);
si rÈussi alors Ècrire("Suppression rÈussie !");
sinon Ècrire("Echec de la suppression !");
fsi
fcas
action = 3 -> cas
Ècrire("fournissez les donnÈes (ID, NOM, PRENOM) :");
avec ligne faire
lire(ID, NOM, PRENOM);
favec;
modifier_ligne(rel, ligne, rÈussi);
si rÈussi alors Ècrire("Modification rÈussie !");
sinon Ècrire("Echec de la modification !");
fsi
fcas
fchoix
fin
proc recherche(val rel : relation)
var rÈussi : boolean;
dÈbut
Ècrire("fournissez la clÈ de l'enregistrement (ID):");
lire(ident);
rechercher_ligne(rel, ident, ligne, reussi);
si rÈussi alors
Ècrire("La recherche a rÈussi :\n");
Ècrire(ligne);
sinon Ècrire("La recherche a ÈchouÈ !");
fsi
fin
dÈbut
tableau := PERSONNEL;
Ècrire("1 - Ajout d'un enregistrement,\n",
"2 - Modification du tableau,\n",
"3 - Recherche d'un enregistrement.\",
"choix : ");
lire(action);
choix
action = 1 -> cas
affichage(tableau);
fcas
action = 2 -> cas
modification(tableau);
fcas
action = 3 -> cas
recherche(tableau);
fcas
fchoix
finLes types abstraits introduisent la notion de mÈthodologie objet dans les algorithmes.
Un type abstrait est constituÈ de plusieurs constantes, variables et mÈthodes (fonctions ou procÈdures) dont certaines constituent une interface par laquelle un objet pourra Ítre manipulÈ sans pour autant connaÓtre sa mise en oeuvre (ou implÈmentation).
# CrÈation d'un type abstrait #
type abstrait : identificateur
interface
# DÈclaration des mÈthodes #
{fonction* | proc} nom_mÈthode([arguments]){: type*};
...
{fonction* | proc} nom_mÈthodeN([arguments]){: type*};
reprÈsentation
# DÈclaration des variables et constantes #
{var | const} nom : type;
...
{var | const} nomN : type;
algorithmes
# DÈfinitions des mÈthodes #
{fonction* | proc} nom_mÈthode([arguments]){: type*};
...
dÈbut
...
fin
...
{fonction* | proc} nom_mÈthodeN([arguments]){: type*};
...
dÈbut
...
fin
ftypeabstrait
# CrÈation d'un objet #
var identificateur_objet : identificateur_type_abstrait;
# Utilisation des mÈthodes #
identificateur_objet.nom_mÈthode([arguments]);# Utilisation des variables et constantes # Une variable ou une constante dÈclarÈe dans reprÈsentation peut Ítre accÈdÈ dans toutes les mÈthodes du type abstrait.
Les variables peuvent Ègalement Ítre modifiÈes ý partir du bloc d'instructions de ces mÍmes mÈthodes.
# Exemple #
type abstrait : Calculatrice
interface
proc saisie(res valA, valB : rÈel, valOP : opÈration);
proc calcul(val valA, valB : rÈel, valOP : opÈration, res resultat: rÈel);
proc affichage(val valA, valB, resultat : rÈel, valOP : opÈration);
reprÈsentation
type opÈration : ÈnumÈration : ('+','-','*','/');
var valA, valB : rÈel, valOP : opÈration
algorithmes
proc saisie();
dÈbut
Ècrire("Entrez un calcul simple
[Nombre, (+ | - | * | /), Nombre (ex.:10.2, *, 5)] :");
lire(valA, valOP, valB);
fproc
proc calcul(res result: rÈel);
dÈbut
choix
type_calcul = '+' -> cas
result := addition(valA, valB);
fcas
type_calcul = '-' -> cas
result := soustraction(valA, valB);
fcas
type_calcul = '*' -> cas
result := multiplication(valA, valB);
fcas
type_calcul = '/' -> cas
result := division(valA, valB);
fcas
fchoix
fproc
proc affichage(val result : rÈel);
dÈbut
Ècrire("OpÈration : ", valA, " ", valOP, " ", valB, " = ", result);
fproc
fonction addition(val a, b) : rÈel;
dÈbut
rÈsultat (a + b);
ffonction
fonction soustraction(val a, b) : rÈel;
dÈbut
rÈsultat (a - b);
ffonction
fonction multiplication(val a, b) : rÈel;
dÈbut
rÈsultat (a * b);
ffonction
fonction division(val a, b) : rÈel;
dÈbut
rÈsultat (a / b);
ffonction
ftypeabstrait
algorithme
var calc : Calculatrice;
valeur_resultat : rÈel;
dÈbut
calc.saisie();
calc.calcul(valeur_resultat);
calc.affichage(valeur_resultat);
finLa programmation a ÈvoluÈ selon plusieurs Ètapes successives, en passant de l'assembleur ý des langages spÈcialisÈs tels que FORTRAN (1957) et COBOL (1959), puis aux langages procÈduraux comme BASIC (1964), PASCAL (1968) et C (1973) et enfin vers des langages orientÈes objets ý l'image du C++ (1983), Java (1995) et C# (2000).
Une des Ètapes principales fut la programmation structurÈe, appelÈe Ègalement procÈdurale ou impÈrative, dont le principe fondamental Ètait la dÈcmposition d'un programme en de multiples sous-programmes ou modules effectuant chacun une certaine action non ÈlÈmentaire, et partant, permettant de dÈcomplexifier une application de grande taille.
Les langages orientÈs objets sont une nouvelle mÈthode de programmation qui tend ý se rapprocher de notre maniËre naturelle d'apprÈhender le monde. Les L.O.O. se sont surtout posÈ la question "Sur quoi porte le programme ?". En effet, un programme informatique comporte toujours des traitements, mais aussi et surtout des donnÈes. Si la programmation structurÈe s'intÈresse aux traitements puis aux donnÈes, la conception objet s'intÈresse d'abord aux donnÈes, auxquelles elle associe ensuite les traitements. L'expÈrience a montrÈ que les donnÈes sont ce qu'il y a de plus stable dans la vie d'un programme, il est donc intÈressant d'architecturer le programme autour de ces donnÈes.
La programmation orientÈe objet se diffÈrencie radicalement de celle fondÈe sur des procÈdures. La programmation procÈdurale (ou impÈrative) met en oeuvre des fonctionnalitÈs Ècrites sous la forme d'une liste d'instructions ý exÈcuter progressivement, soit les unes aprËs les autres et Èventuellement avec des appels de procÈdures ou de fonctions effectuant chacune une certaine action non ÈlÈmentaire.
La programmation orientÈe objet (POO) est basÈe sur la reprÈsentation par des objets, des entitÈs dÈfinies par l'Ètude du problËme ý rÈaliser.
La POO dÈcompose un programme en de multiples classes, soit des modules autonomes accomplissant certaines t‚ches. Ces classes permettent de crÈer des objets par l'instanciation de ces classes.
Les procÈdures ou fonctions effectuent. En gÈnÈral, une telle action ne peut pas se programmer de la mÍme faÁon pour tous les types de donnÈes (ou objets).La POO permet de dÈvelopper des applications ý partir d'objets, c'est-ý-dire, d'entitÈs possÈdant des propriÈtÈs, des mÈthodes et des ÈvÈnements, ces objets pouvant Ítre une page Web, un formulaire, un tableau, une chaÓne de caractËres, un nombre, une image, etc..
Les propriÈtÈs sont des mÈthodes fournissant un accËs ý des valeurs simulant celles des champs. Les propriÈtÈs (ou attributs)d'un objet contiennent les valeurs relatives ý cet objet, telles que la taille d'un tableau, le type de donnÈes d'un nombre, la contenu d'une chaÓne de caractËres, etc..
Les propriÈtÈs peuvent Ítre simplement lues pour une affectation ou pour un affichage, ainsi que modifiÈes pour un paramÈtrage de l'objet ý certaines valeurs.
Les mÈthodes d'un objet reprÈsentent les opÈrations que cet objet peut accomplir comme l'ajout d'une valeur dans un tableau, la concatÈnation d'une chaÓne de caractËres, la conversion du type de donnÈes d'un nombre.
Les ÈvÈnements d'un objet consistent en la capture d'une action sur cet objet, ý l'image d'un clic de souris sur un bouton, la soumission d'un formulaire, le chargement et dÈchargement d'une page Web.
Les objets sont issus d'une instanciation de classe, ces derniËres lui fournissant des propriÈtÈs, des mÈthodes et des ÈvÈnements, soit les membres de cette classe.
Une classe est un type rÈfÈrence encapsulant des donnÈes (champs et constantes), ainsi qu'un comportement (mÈthodes, propriÈtÈs, indexeurs, ÈvÈnements, opÈrateurs, constructeurs et destructeurs), pouvant contenir des types imbriquÈs.
Les champs reprÈsentent des variables contenant des valeurs.
Les constantes reprÈsentent des champs contenant des valeurs fixes.
Les indexateurs permettent d'indexer un objet par l'intermÈdiaire des mÈthodes d'accËs get et set.
Les opÈrateurs permettent d'inclure les opÈrations mathÈmatiques de base dans les classes par l'intermÈdiaire de la surcharge des opÈrateurs.
SommaireLes langages orientÈs objets assimilent trois concepts fondamentaux :
- l'encapsulation,
- l'hÈritage,
- et le polymorrphisme.
EncapsulationL'encapsulation consiste en la capacitÈ d'un objet ý masquer ses donnÈes et mÈthodes internes, rendant uniquement accessibles les parties prÈvues de l'objet par le programme.
L'encapsulation est la capacitÈ que possËde un objet de masquer certains de ses ÈlÈments tout en fournissant un accËs ý d'autres ÈlÈments constituant l'interface utilisateur.
Les mÈthodes et les propriÈtÈs d'un objet peuvent Ítre divisÈes en membres visibles nÈcessaires au paramËtrage et aux opÈrations de l'objet demandÈs par l'utilisateur, et en membres invisibles participant ý l'implÈmentation de l'objet.
L'utilisation des modificateurs d'accËs permet d'appliquer les principes d'encapsulation, en dÈfinissant des niveaux de visibilitÈ (privÈ, public, protÈgÈ) des membres d'une classe.
AbstractionL'abstraction permet d'accroÓtre la concentration des programmeurs sur la modÈlisation d'un problËme par du code plutÙt que sur la maniËre dont les rÈsultats seront obtenus.
Un nom clair, exprimÈ en langage naturel, pour une classe permettra de connaÓtre avec certitude quelles fonctionnalitÈs accomplissent cette classe.
Ainsi, l'utilisation d'une classe sera d'autant plus intuitive si son nom est explicite, tout comme ceux de ses interfaces et de ses membres.
HÈritageL'hÈritage consiste en la crÈation d'une classe ý partir d'une classe existante, permettant de construire une hiÈrarchie de classes.
La nouvelle classe hÈrite automatiquement de l'ensemble des membres de la classe de base et par consÈquent, de toutes les fonctionnalitÈs de cette derniËre.
PolymorphismeLe polymorphisme caractÈrise la possibilitÈ de dÈfinir plusieurs mÈthodes avec un nom identique, mais des paramËtres diffÈrents. La mÈthode attendue est, alors, choisie en fonction des paramËtres fournis lors de son appel.
Le polymorsphisme permet d'appeler prÈcisÈment la mÈthode de la classe instanciant l'objet en cours, dans une hiÈrarchie de classes. Ainsi, un objet issu d'une classe dÈrivÈe pourra appeler la mÈthode de cette derniËre, tout en laissant de cÙtÈ les autres mÈthodes de mÍme nom dans la hiÈrarchie de classes du programme.
Le polymorphisme constitue, Ègalement, un moyen d'extension d'un programme sans nÈcessiter la modification du code existant.
Le couple PHP/MySQL associe un langage de script multi-plateformes ý un systËme de base de donnÈes efficace, dans le but de crÈer des applications Web dynamiques. PHPMyAdmin est une interface graphique Ècrite en PHP et destinÈe ý la manipulation et ý la gestion de base de donnÈes MySQL.
phpMyAdmin possËde les fonctions suivantes :
- CrÈation et suppression des bases de donnÈes,
- Gestion des privilËges d'accËs aux bases de donnÈes,
- Ajout, Èdition et suppression d'enregistrements et de champs
- ExÈcution de requÍtes SQL,
- Gestion des clÈs et index sur les donnÈes,
- Optimisation des tables de donnÈes,
- Importation ou exportation des donnÈes ý partir d'archives compressÈes ou de fichiers texte, CVS ou XML
- Administration d'un ou plusieurs serveurs de base de donnÈes et d'uniques base de donnÈes
En premier lieu, il faut tÈlÈcharger les derniËres versions stables de ces outils.
- PHP : http://www.php.net/downloads.php
- MySQL : http://www.mysql.com/downloads/index.html
- PHPMyAdmin : http://www.phpmyadmin.net/
En ce qui concerne PHP, il est plus simple de tÈlÈcharger la version PHP XXX installer permettant une installation automatisÈe ý l'aide d'un exÈcutable .exe et Ègalement la version compressÈe au format ZIP contenant plusieurs fichiers importants.
Une fois en possession de ces derniers, une dÈcompression des fichiers s'impose afin d'obtenir les fichiers installables.

A ce stade, vous lancez l'application PHP XXX installer, en repÈrant le rÈpertoire d'installation, en gÈnÈral C:\PHP, dans lequel vous collerez ensuite, le contenu du dossier php-XXX-Win32.
L'installation de MySQL ne nÈcessite qu'un simple double-clic sur le fichier setup.exe prÈsent dans le rÈpertoire mysql-XXX-win.
Le contenu du dossier phpMyAdmin-XXX doit Ítre recopiÈ ý la racine du site Web par dÈfaut, soit dans le rÈpertoire www ou wwwroot. Par ailleurs, il peut Ítre prÈfÈrable de renommer le dossier phpMyAdmin-XXX en phpMyAdmin, permettant un accËs simple et court ý l'interface d'administration (http://www.site.net/phpmyadmin/).
DÈsormais, il faut configurer l'ensemble de ces outils afin que chacun fonctionne dans la plÈnitude de leurs moyens et se reconnaisse sans problËme.
Dans un premier temps, il faut copier tous les fichiers .dll et autres prÈsents dans les rÈpetoires c:\php\dlls\ et c:\php\extensions\ dans le dossier system32 ou system (si le premier n'existe pas) de Windows.
L'Èdition par le bloc-notes du fichier php.ini localisÈ dans le rÈpertoire de Windows, en gÈnÈral c:\windows ou encore c:\winnt, doit permettre de configurer les extensions PHP.
;Extrait du fichier php.ini ;Windows Extensions ;Note that MySQL and ODBC support is now built in, ;so no dll is needed for it. ; extension=php_bz2.dll extension=php_cpdf.dll extension=php_crack.dll extension=php_curl.dll extension=php_db.dll extension=php_dba.dll extension=php_dbase.dll extension=php_dbx.dll extension=php_domxml.dll extension=php_exif.dll ;extension=php_fbsql.dll ;extension=php_fdf.dll ;extension=php_filepro.dll extension=php_gd.dll ;extension=php_gd2.dll extension=php_gettext.dll ;extension=php_hyperwave.dll extension=php_iconv.dll ;extension=php_ifx.dll ;extension=php_iisfunc.dll extension=php_imap.dll ;extension=php_interbase.dll extension=php_java.dll extension=php_ldap.dll extension=php_mbstring.dll ;extension=php_mcrypt.dll extension=php_mhash.dll extension=php_mime_magic.dll extension=php_ming.dll extension=php_mssql.dll extension=php_msql.dll ;extension=php_oci8.dll extension=php_openssl.dll ;extension=php_oracle.dll extension=php_pdf.dll extension=php_pgsql.dll extension=php_printer.dll extension=php_shmop.dll extension=php_snmp.dll extension=php_sockets.dll ;extension=php_sybase_ct.dll extension=php_w32api.dll extension=php_xmlrpc.dll extension=php_xslt.dll extension=php_yaz.dll extension=php_zip.dll
Le point-virgule permet de dÈsactiver l'extension attenante. Chacune des extensions actives dans PHP doit obligatoirement se trouver dans le rÈpertoire c:\php\extensions\, sinon un message d'erreur apparaitra lors du lancement de PHP.
La vÈrification de la bonne installation des extensions PHP, peut s'effectuer par l'intermÈdiaire de l'instruction phpinfo().
Pour cela, il suffit de crÈer un document PHP, lequel sera dÈnommÈ phpinfo.php et enregitrÈ sous la racine de votre site Web par dÈfaut.
<?php phpinfo(); ?>
Le chargement de ce fichier affichera toutes les informations relatives ý PHP. Si des erreurs d'installation subsistent, des messages d'erreurs seront affichÈs.
Si votre systËme utilise le kit de dÈveloppement Java (JDK), vous devrez modifier en consÈquence le fichier php.ini.
;Extrait du fichier php.ini [Java] java.class.path = .\php_java.jar java.home = C:\j2sdk java.library = C:\j2sdk\jre\bin\hotspot\jvm.dll java.library.path = .\
Vous pouvez de mÍme modifier la variable register_globals afin d'autoriser l'utilisation des variables globales.
register_globals = On
De mÍme, plusieurs autres domaines peuvent Ítre configurÈs dans ce fichier de configuration de PHP, tels que les chemins et rÈpertoires (Paths and Directories), les sessions, le tÈlÈchargement de fichiers (File Uploads), etc..
Les accËs aux bases de donnÈes peuvent Ègalement Ítre configurÈs dans le fichier php.ini, mais cela n'est pas recommandÈ pour des raisons de sÈcuritÈ.
La configuration de PHPMyAdmin s'effectue par l'entremise du fichier config.inc.php situÈ dans le rÈpertoire phpMyAdmin.
//Extrait du fichier config.inc.php ... $cfg['Servers'][$i]['host'] = 'localhost'; // MySQL hostname $cfg['Servers'][$i]['port'] = ''; // MySQL port - leave blank for default port ... $cfg['Servers'][$i]['auth_type'] = 'config'; // Authentication method (config, http or cookie based)? $cfg['Servers'][$i]['user'] = 'root'; // MySQL user $cfg['Servers'][$i]['password'] = ''; // MySQL password (only needed with 'config' auth_type) ...
Lors de l'installation de MySQL, un compte par dÈfaut est automatiquement crÈÈ, il s'agÓt de l'utilisateur root sans mot de passe.
Donc, il est possible d'ouvrir l'interface d'administration PHPMyAdmin avec la configuration par dÈfaut, mais cela devra Ítre immÈdiatement rectifiÈ pour des raisons de sÈcuritÈ Èvidentes.
L'ouverture de l'interface s'accomplit en lanÁant son navigateur Web, puis en saisissant dans la barre d'adresse le chemin adÈquat.
http://www.site.com/phpMyAdmin/index.php ou http://localhost/phpMyAdmin/index.php
A partir de lý, vous cliquez sur le lien PrivilËges prÈsent sur la page de droite.
La table user contient les comptes d'utilisateurs du systËme de gestion de base de donnÈes de MySQL.
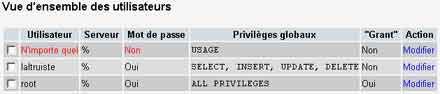
Modifiez le compte d'utilisateur root en spÈcifiant un mot de passe dans les champs appropriÈs.
En rechargeant PHPMyAdmin, on pourra remarquer que l'accËs ý l'interface graphique est refusÈe puisque la configuration initiale du fichier config.inc.php n'est plus valable.
Dans ce cas, il suffit d'Èditer le fichier prÈcitÈ et d'affecter le mot de passe correspondant ý la variable $cfg['Servers'][$i]['password'].
Le documents PDF (Portable Document Format) possËdent la particularitÈ de pouvoir Ítre lus indÈpendamment de toutes plateformes (Windows, Mac, Linux, etc.) tout en conservant rigoureusement la mise en page.
NÈanmoins, le format PDF a ÈtÈ conÁu par l'Èditeur de logiciels graphiques, Adobe (Acrobat Reader, Photoshop, Premiere, Golive, etc.) et demeure donc un format propriÈtaire que la plupart des logiciels d'Èdition ne gËre pas.
Heureusement, il n'est pas utile de s'Èquiper du trËs co˚teux logiciel, Adobe Acrobat. De simples utilitaires souvent gratuits o˘ d'un co˚t modique suffiront ý crÈer des documents PDF ý l'allure professionnelle.
Il est possible d'opter pour diffÈrentes solutions, telles que le couple Ghostview et Ghostscript (Windows, Mac, Linux), HTMLDOC (Windows, Linux), PDF995 (Windows) ou encore d'autres.
Dans un premier temps, il vous faudra tÈlÈcharger les logiciels choisis et les installer sur votre configuration.
- En ce qui concerne Windows, il suffit de lancer les fichiers exÈcutables et suivre la procÈdure d'installation.
- Pour Linux, vous avez parfois le choix entre des fichiers .rpm se comportant comme des fichiers exÈcutables Windows ou les archives .tar.gz.
DÈcompression de l'archive Archive.source.tar.gz % tar xzf Archive-source.tar.gz Installation du logiciel % cd Archive % ./configure % make
- Au niveau du Mac, il suffit de double-cliquez sur les fichiers d'installation.
Il est souhaitable Ègalement de tÈlÈcharger et installer l'utilitaire Adobe Acrobat reader afin de vÈrifier d'une maniËre optimum vos travaux.
Maintenant, il est nÈcessaire d'installer un pilote d'impression postscript sur votre configuration Windows. En principe, la plupart des distributions Linux, installe directement un pilote d'impression Postscript, voire mÍme un pilote PDF.
- Cliquez sur le menu DÈmarrer -> ParamËtres -> Imprimantes,
- Double-cliquez sur Ajout d'imprimante,
- A l'ouverture de l'Assistant Ajout d'imprimante, cliquez sur Suivant,
- Si besoin est, cochez Imprimante locale, puis cliquez sur Suivant,
- SÈlectionnez le port imprimante, en ganÈral LTP1, puis cliquez sur Suivant,
- SÈlectionnez une imprimante Laser Postscrit de prÈfÈrence comme l'HP Color LaserJet 8500 PS, puis cliquez sur Suivant,
- Donnez un nom ý l'imprimante, puis cliquez sur Suivant,
- Donnez Èventuellement un nom de partage ý cette imprimante, puis cliquez sur Suivant,
- Cliquez sur Suivant jusqu'ý la fin de l'Assistant Ajout d'imprimante, et enfin cliquez sur Terminer pour valider l'installation.
Pour vÈrifier le bon fonctionnement de cet installation, ouvrez un document textuel ou une page html quelconque, puis cliquez sur Fichier -> Imprimer. SÈlectionnez l'imprimante Postscript (par ex.: HP Color LaserJet 8500 PS) et validez l'impression. Normalement une boÓte de dialogue devrait vous demander de saisir le nom du fichier de sortie.
Lorsque vous imprimez dans un tel fichier, l'extension de ce dernier doit donc Ítre gÈnÈralement .ps.
nom_du_fichier_dimpression.ps
A partir de ce genre de fichier, Ghostview peut crÈer trËs facilement un fichier PDF. Il suffit d'ouvrir le fichier Postscript avec le logiciel, puis de le convertir en cliquant sur File -> Convert.... Dans la boÓte de dialogue, il faut choisir le type pdfwrite et une rÈsolution. AprËs la validation, le nom du fichier de sortie est demandÈ avant d'obtenir un document PDF.
La gÈnÈration d'un fichier postscript est possible ý partir de n'importe quelle application en effectuant une impression vers un fichier. Ensuite Ghostview se charge de convertir le document postscript dans le format PDF.
Avec PDF995, la procÈdure demeure semblable ý l'exception du format du document rÈsulant de l'impression vers un fichier. En effet, PDF995 gÈnÈre directement le fichier PDF et donc ne nÈcessite pas de passer par une phase de conversion. Egalement, lors de l'installation du logiciel, PDF995 installe sa propre imprimante postcript locale portant d'ailleurs le nom de l'application.
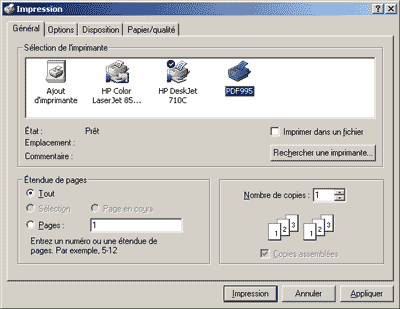
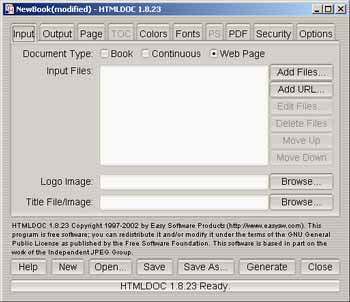
Quant ý HTMLDOC, la procÈdure est diffÈrente :
- Dans ce cas, il faut ouvrir le logiciel,
- Ajouter soit des fichiers, soit des adresses URL et sÈlectionner l'option Web Page ý partir de l'onglet Input,
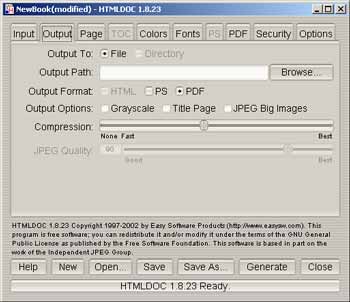
- Puis sÈlectionner le format PDF et saisir le nom du fichier de sortie ý partir de l'onglet Output.
- Enfin, un clic sur Generate permet de gÈnÈrer le document PDF.
HTMLDOC autorise l'enchaÓnement de plusieurs documents distincts afin de ne produire qu'un seul et unique fichier PDF. De plus, il est le seul des trois logiciels ý crÈer automatiquement des liens au sein des documents PDF rÈsultants. En outre, diverses options permettent de rÈgler plus prÈcisÈment les marges, les couleurs, ainsi que l'encryptage.
Il reste donc simple et rapide de crÈer des documents PDF ý partir de quasiment n'importe quelle source, puisqu'il suffit dans la plupart des cas d'imprimer vers un fichier postscript puis de convertir ce dernier dans le format PDF.
Les lignes de commande utilisables aussi bien sur Windows que Linux ou d'autres systËmes d'exploitation, permettent de lancer des actions monot‚ches ý partir de l'invite de commandes MS-DOS ou de la console Linux.
Chaque commande MS-DOS ou Linux propose une aide en ligne en utilisant respectivement les options /? ou --h et --help. Il est possible Ègalement d'utiliser les commandes spÈcifiques d'aide, c'est-ý-dire help pour MS-DOS et man pour Linux.
SommaireWindows mkdir /? help shift Linux tty --help man ls
Les commandes MS-DOS permettent d'exÈcuter des t‚ches ý partir de l'invite de commandes, parfois trËs utiles dans le cadre de dÈveloppement avec des langages comme Java ou C#.
| Commande | Description |
|---|---|
| ASSOC | Affiche ou modifie les applications associÈes aux extensions de fichiers. |
| AT | Planifie l'exÈcution de commandes ou programmes sur un ordinateur. |
| ATTRIB | Affiche ou modifie les attributs d'un fichier. |
| BREAK | Active ou dÈsactive le contrÙle Ètendu de CTRL+C. |
| CACLS | Affiche ou modifie les listes de contrÙles d'accËs aux fichiers. |
| CALL | Appelle un fichier de commandes depuis un autre fichier de commandes. |
| CD | Modifie le rÈpertoire ou affiche le rÈpertoire en cours. |
| CHCP | Modifie la page de code active ou affiche son numÈro. |
| CHDIR | Modifie le rÈpertoire ou affiche le nom du rÈpertoire en cours. |
| CHKDSK | VÈrifie un disque et affiche un relevÈ d'Ètat. |
| CLS | Efface l'Ècran. |
| CMD | Lance une nouvelle instance de l'interprÈteur de commandes de Windows 2000. |
| COLOR | Modifie les couleurs du premier plan et de l'arriËre plan de la console. |
| COMP | Compare les contenus de deux fichiers ou groupes de fichiers. |
| COMPACT | Modifie ou affiche la compression des fichiers sur une partition NTFS. |
| CONVERT | Convertit des volumes FAT en volumes NTFS. Vous ne pouvez pas convertir le lecteur en cours d'utilisation. |
| COPY | Copie un ou plusieurs fichiers. |
| DATE | Affiche ou modifie la date. |
| DEL | Supprime un ou plusieurs fichiers. |
| DIR | Affiche la liste des fichiers et des sous-rÈpertoires d'un rÈpertoire. |
| DISKCOMP | Compare les contenus de deux disquettes. |
| DISKCOPY | Copie le contenu d'une disquette sur une autre. |
| DOSKEY | Modifie les lignes de commande, rappelle des commandes Windows 2000, et permet de crÈer des macros. |
| ECHO | Affiche des messages ý l'Ècran ou active/dÈsactive l'affichage des commandes. |
| ENDLOCAL | Stoppe la localisation des modifications de l'environnement dans un fichier de commandes. |
| ERASE | Supprime un ou plusieurs fichiers. |
| EXIT | Quitte l'interprÈteur de commandes (CMD.EXE). |
| FC | Compare deux fichiers ou groupes de fichiers, et affiche les diffÈrences entre eux. |
| FIND | Cherche une chaÓne de caractËres dans un ou plusieurs fichiers. |
| FINDSTR | Cherche des chaÓnes de caractËres dans un ou plusieurs fichiers. |
| FOR | ExÈcute une commande sur chaque fichier d'un groupe de fichiers. |
| FORMAT | Formate un disque pour utilisation avec Windows 2000. |
| FTYPE | Affiche ou modifie les types de fichiers utilisÈs dans les associations d'extensions. |
| GOTO | Poursuit l'exÈcution d'un fichier de commandes ý une ligne identifiÈe par une Ètiquette. |
| GRAFTABL | Permet ý Windows 2000 d'afficher un jeu de caractËres en mode graphique. |
| HELP | Affiche des informations sur les commandes de Windows 2000. |
| IF | Effectue un traitement conditionnel dans un fichier de commandes. |
| LABEL | CrÈe, modifie ou supprime le nom de volume d'un disque. |
| MD | CrÈe un rÈpertoire. |
| MKDIR | CrÈe un rÈpertoire. |
| MODE | Configure un pÈriphÈrique du systËme. |
| MORE | Affiche la sortie Ècran par Ècran. |
| MOVE | DÈplace un ou plusieurs fichiers d'un rÈpertoire ý un autre. |
| PATH | Affiche ou dÈfinit le chemin de recherche des fichiers exÈcutables. |
| PAUSE | Interrompt l'exÈcution d'un fichier de commandes et affiche un message. |
| POPD | Restaure la valeur prÈcÈdente du rÈpertoire courant enregistrÈ par PUSHD. |
| Imprime un fichier texte. | |
| PROMPT | Modifie l'invite de commande de Windows 2000. |
| PUSHD | Enregistre le rÈpertoire courant puis le modifie. |
| RD | Supprime un rÈpertoire. |
| RECOVER | RÈcupËre l'information lisible d'un disque dÈfectueux. |
| REM | InsËre un commentaire dans un fichier de commandes ou CONFIG.SYS. |
| REN | Renomme un ou plusieurs fichiers. |
| RENAME | Renomme un ou plusieurs fichiers. |
| REPLACE | Remplace des fichiers. |
| RMDIR | Supprime un rÈpertoire. |
| SET | Affiche, dÈfinit ou supprime des variables d'environnement Windows 2000. |
| SETLOCAL | Commence la localisation des changements de l'environnement dans un fichier de commandes. |
| SHIFT | Modifie la position des paramËtres remplaÁables dans un fichier de commandes. |
| SORT | Trie les ÈlÈments en entrÈe. |
| SUBST | Affecte une lettre de lecteur ý un chemin d'accËs. |
| START | Lance une fenÍtre pour l'exÈcution du programme ou de la commande. |
| TIME | Affiche ou dÈfinit l'heure de l'horloge interne du systËme. |
| TITLE | DÈfinit le titre de la fenÍtre pour une session CMD.EXE. |
| TREE | ReprÈsente graphiquement l'arborescence d'un lecteur ou d'un chemin. |
| TYPE | Affiche le contenu d'un fichier texte. |
| VER | Affiche le numÈro de version de Windows 2000. |
| VERIFY | Indique ý Windows 2000 s'il doit ou non vÈrifier que les fichiers sont Ècrits correctement sur un disque donnÈ. |
| VOL | Affiche le nom et le numÈro de sÈrie du volume. |
| XCOPY | Copie des fichiers et des arborescences de rÈpertoires. |
Les lignes de commandes sont particuliËrement importantes dans l'environnement Linux. Elles permettent d'exÈcuter des t‚ches parfois trËs utiles dans le cadre de dÈveloppement d'application, de maintenance ou encore de configuration du systËme.
| Commande | Description |
|---|---|
| alias | dÈfinit des abrÈviations pour les appels de commandes. |
| at | exÈcute une commande ý un moment prÈcis. |
| awk (gawk) | une implÈmentation GNU du langage awk permettant le traitement de fichiers. |
| banner | imprime une banniËre (sortie de caractËres en majuscule ). |
| basename | extrait le nom de fichier d'un chemin d'accËs. |
| bg | place un processus en arriËre plan. |
| break | termine une boucle. |
| cal | affiche le calendrier. |
| case | une structure de contrÙle ý choix multiples. |
| cat | affiche le contenu d'un fichier. |
| cd | change de rÈpertoire actif. |
| chgrp | change l'affectation de groupe pour des fichiers. |
| chmod | change les droits d'accËs des fichiers. |
| chown | change le propriÈtaire d'un fichier. |
| chroot | change le rÈpertoire racine pour l'exÈcution d'une commande. |
| cmp | compare deux fichiers. |
| continue | reprend une boucle interrompue avant son terme. |
| cp | copie des fichiers. |
| cpio | copie un fichier d'archive pour la sauvegarde. |
| crontab | exÈcute des commandes ý intervalles rÈguliers. |
| cut | dÈcoupe des morceaux de lignes. |
| date | retourne et rÈgle la date systËme. |
| dd | copie et convertit des donnÈes. |
| df | affiche l'espace disponible sur un support de donnÈes. |
| diff | dÈtermine les diffÈrences entre les fichiers. |
| du | dÈtermine l'espace disque utilisÈ. |
| echo | affiche une ligne de texte. |
| egrep | recherche ý l'aide d'une expression rÈguliËre Ètendue. |
| env | modifie l'environnement d'une commande. |
| eval | Èvalue une commande shell. |
| exit | quitte le shell courant. |
| export | exporte les variables du shell. |
| expr | utilise et calcule des expressions. |
| false | exprime la valeur de retour standard des shelles scripts. |
| fc | rappelle une ligne de commande. |
| fg | place une commande d'arriËre-plan au premier plan. |
| fgrep | recherche sans expression rÈguliere. |
| file | affiche le type de fichier. |
| find | recherche rÈcursivement des fichiers. |
| for | ireprÈsente une structure de controle. |
| gcc | reprÈsente le compilateur C GNU. |
| grep | recherche avec des expressions rÈguliËres. |
| id | affiche des identificateurs d'utilisateurs et de groupes. |
| if | reprÈsente une condition dans un script shell. |
| jobs | affiche des processus d'arriËre plan en cours. |
| join | joint deux fichiers. |
| kill | envoie un signal ý un processus. |
| let | affectate arithmÈtiquement dans le shell. |
| ln | affecte un lien ý un fichier. |
| logname | afficher le nom d'utilisateur. |
| lpq | dÈtermine l'Ètat des files d'attentes d'impression. |
| lpr | imprime des fichiers. |
| lprm | annule une requÍte d'impression. |
| ls | liste les fichiers d'un rÈpertoire. |
| lit et envoie des messages. | |
| man | appelle de l'aide en ligne. |
| mesg | fournit des accËs aux terminaux. |
| mkdir | crÈe un rÈpertoire. |
| mknod | crÈe des fichiers de pÈriphÈrique et de FIFOs. |
| more | affiche des fichiers et donnÈes page par page. |
| mv | dÈplace des fichiers. |
| newgrp | modifie l'appartenance ý un groupe. |
| nice | lance une commande avec des prioritÈs modifiÈs. |
| nohup | ignore les signaux dans le cadre d'une commande. |
| od | affiche des donnÈes dans le format interne. |
| passwd | modifie le mot de passe utilisateur. |
| pg | visualise les fichiers et les donnÈes page par page. |
| pr | formate des donnÈes et des fichiers. |
| ps | affiche des informations sur l'etat des processus en cours. |
| pwd | affiche le rÈpertoire actif. |
| read | lit des valeurs. |
| readonly | protÈge des variables du shell contre la rÈÈcriture. |
| return | retourne une valeur ý partir d'une fonction du shell. |
| rm | supprimr un fichier. |
| rmdir | supprime un rÈpertoire. |
| sed | reprÈsente un Èditeur de texte batch. |
| select | reprÈsente une sÈlection de menu simple dans le shell. |
| set | fixe des options et des paramËtres de position. |
| shift | convertit des paramËtres de position. |
| sleep | reprÈsente une interruption du traitement pendant un certain temps. |
| sort | trie des donnÈes et des fichiers ligne par ligne. |
| stty | configure une interface sÈrie. |
| su | change de numÈro d'utilisateur. |
| sync | sauvegarde de la mÈmoire tampon d'entrÈes/sorties. |
| tail | affiche la fin d'un fichier ou d'un ensemble de donnÈes. |
| tar | sauvegarde et archive des fichiers. |
| tee | duplique un flux de donnÈes. |
| test | effectue un test sur une condition. |
| time | calcule la durÈe d'exÈcution d'une commande. |
| touch | modifie la date d'accÈs ou de modification. |
| tr | convertit des caractËres. |
| trap | gËre des rÈactions aux signaux. |
| true | reprÈsente la valeur standard pour un shell script. |
| tty | affiche le nom des terminaux. |
| typeset | modifie les valeurs d'attributs des variables du shell. |
| ulimit | fixe la taille maximale d'un fichier. |
| umask | dÈfinit des droits d'accËs prÈdÈfinis. |
| unalias | supprime un nom d'alias. |
| uname | demande le nom du systËme. |
| unset | supprime des dÈfinitions de variables et de fonctions. |
| until | reprÈsente une structure de contrÙle de boucles. |
| vi | appelle l'Èditeur orientÈ Ècran. |
| wait | temporise un processus en arriËre-plan. |
| wall | envoie un message ý tous les utilisateurs. |
| wc | compte des caractËres, des mots et des lignes. |
| while | reprÈsente une structure de contrÙle de boucles. |
| who | affiche la liste des utilisateurs connectÈs. |
| write | Ècrit un message ý d'autres utilisateurs. |
| xargs | combine des lignes de commandes et de saisie de clavier. |
Les fichiers batch permettent d'exÈcuter une sÈrie d'instructions passÈes en ligne de commandes. Cela fonctionne sur les invites de commandes proposÈe par Windows (MS-DOS) ou Linux (Terminaux).
Les fameux Ècrans noirs invitent l'utilisateur ý saisir des instructions afin d'effectuer des t‚ches prÈcises.
Affichage de la date courante c:\>date /T [Validez] Affichage de l'heure courante c:\>time /T [Validez] Changement de rÈpertoire c:\>cd .\travail\trimestre2\ [Validez] Edition d'un fichier c:\travail\trimestre2\>edit cours.txt [Validez]
Parfois, il peut Ítre utile de lancer plusieurs instructions les unes ý la suite des autres afin d'atteindre un but prÈcis.
c:\>d: [Validez] d:\>cd travail [Validez] d:\travail\>cd cours [Validez] d:\travail\cours\>cd temporaire [Validez] d:\travail\cours\temporaire\>del *.* [Validez] d:\travail\cours\temporaire\>cd .. [Validez] d:\travail\cours\>rd temporaire [Validez]
Dans ce cas, plutÙt que de taper cette suite de commandes, surtout si elle est destinÈe ý Ítre rÈpÈtÈe, il sera prÈfÈrable d'utiliser un fichier batch.
rem Fichier : effacement.bat rem Empeche l'inscription des lignes de commandes ! @echo off rem Efface la console cls rem Affiche du texte a l'ecran echo Effacement du repertoire temporaire et de ses fichiers rem Marque une pause pause d: cd travail cd cours cd temporaire del *.* cd .. rd temporaire echo Les fichiers temporaires et le rÈpertoire ont bien ete effaces !
L'enregistrement de ce genre de texte dans un fichier portant l'extension .bat pour Windows et .sh pour Linux, puis l'appel de ce fichier ý partir de la console, permettront de lancer automatiquement le traitement attendu.
c:\>effacement.bat [Validez]
Une particularitÈ importante des fichiers batch est qu'ils peuvent recevoir de un ý neuf arguments.
rem Fichier : bienvenue.bat @echo off echo Bienvenue %1 ! c:\>bienvenue Frederic [Validez] Bienvenue Frederic !
En fait, il existe dix arguments possible, il s'agÓt du nom du fichier batch lui mÍme, portant la rÈfÈrence %0.
rem Fichier argument.bat @echo off cls echo %0 C:\argument [Validez] c:\argument
De cette maniËre, l'utilisateur du fichier batch pourra saisir des informations particuliËres au traitement attendu.
rem Fichier : suppression.bat @echo off cls %1: cd %2 del *.* echo Effacement des fichiers ! cd \ rem Si le troisieme argument est egal a n alors allez a fin if "%3"=="n" goto fin rd %2 echo Effacement du repertoire %2 ! rem Etiquette de fin :fin C:\>suppression d repertoire o [Validez] D:\dd\*.*, tes-vous s˚r (O/N)Ý? o Effacement des fichiers ! Effacement du repertoire dd ! D:\>
Dans cet exemple, une instruction conditionnelle if est utilisÈ afin de tester un argument et en fonction de ce dernier un certain traitement sera ou ne sera pas appliquÈ. En l'occurrence, le troisiËme argument dÈtermine si le rÈpertoire cible doit Ítre effacÈ aprËs les fichiers.
Il est possible d'utiliser plus de neuf arguments ý l'aide d'une commande de dÈcalage : shift.
rem Fichier : arguments.bat @echo off :continue if "%1"=="" goto fin echo %1 shift goto continue :fin echo Lecture des arguments terminee ! C:\>arguments 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [Validez] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Lecture des arguments terminee !
Les fichiers batch peuvent Ègalement utiliser des variables, initialisÈes ý l'aide de la commande set.
rem Fichier variable.bat @echo off set repertoire=%1 set fichier=%2 if exist %repertoire% goto suite echo Le repertoire %repertoire% est introuvable ! goto fin :suite echo Le repertoire %repertoire% a ete trouve ! cd %repertoire% if exist %fichier% goto suivant echo Le fichier %fichier% est introuvable ! goto fin :suivant echo Le fichier %fichier% a ete trouve ! type %fichier% echo .../... echo Traitement termine ! :fin C:\>variable repertoire fichier.txt [Validez] Le repertoire repertoire a ete trouve ! Le fichier fichier.txt a ete trouve ! Le contenu du fichier .../... Traitement termine ! E:\repertoire\>
Les variables ne peuvent dÈlivrer leur contenu qu'ý condition d'encadrer leur identificateur avec des signes de pourcentage %, sinon sera utilisÈ dans une expression, l'identificateur de la variable, et non sa valeur.
Une autre commande intÈressante n'existe malheureusement plus dans les versions rÈcentes de Windows. Il s'agÓt de la commande choice procurant une structure de choix particuliËrement utile et puissante.
rem Fichier : choix.bat :menu echo A - Compilez un fichier source echo B - ExÈcutez un fichier classe echo C - Consultez un fichier source echo D - Quittez le menu echo E - Fermez la console choice /c:abcde if "%errorlevel%"=="A" goto compil if "%errorlevel%"=="B" goto exec if "%errorlevel%"=="C" goto edite if "%errorlevel%"=="D" goto fin if "%errorlevel%"=="D" goto quit :compil javac %1.java goto menu :exec java %1 goto menu :edite edit %1.java goto menu :quit exit :fin C:\>choix fichier
Les fichiers batch proposent donc une solution simple pour automatiser des t‚ches rÈpÈtitives et plus ou moins complexes. Par exemple dans le cas des compilations Java, il peut Ítre souhaitable d'initialiser certaines variables d'environnement nÈcessaires.
rem Fichier : compilexec.bat
@echo off
set path=c:\j2sdk\bin\;%PATH%
if not "%3"=="" goto init
set repertoire=%1
set fichier=%2
goto suite
:init
set repertoire=%2
set fichier=%3
:suite
set classpath=c:\%repertoire%\classes\
set source=c:\%1\sources\
set direction=c:\%1\classes\
javac -classpath %classpath%
-d %direction% %source%%fichier%.java
echo La compilation a ete accomplie avec succes !
java -classpath %classpath% %fichier%
echo L'execution s'est deroulee avec succes !
C:\compilexec projet repertoire fichier.java [Validez]
La compilation a ete accomplie avec succes !
...
L'execution s'est deroulee avec succes !Un systËme informatique (SI) est composÈ de deux parties : le matÈriel (hardware) et le logiciel (software). Un SI permet de traiter des informations reÁues en entrÈe, et retourne d'autres informations en sortie.
Par exemple, deux nombres et un opÈrateur d'addition sont fournis par un opÈrateur via un clavier et le SI retourne sur un Ècran, le rÈsultat d'un traitement applicatif qui est la somme des deux nombres. Dans ce cas, en parfaite symbiose, le logiciel et le matÈriel ont concouru ý la saisie de donnÈes d'entrÈe, au traitement des informations et ý l'affichage de donnÈes de sortie.
Le matÈriel est un ensemble de composants destinÈ ý acquÈrir des informations extÈrieures (clavier, souris, webcam, scanner, etc.), ý accomplir des traitements internes (processeur, CPU : Central Processing Unit, etc.), ý stocker des informations dans des mÈmoires de masse (disque dur, disquette, cÈdÈrom, DVD ROM, etc.) et ý restituer le rÈsultat des traitements (Ècran, imprimante, carte son, etc.).
Le matÈriel est une machine possÈdant des entrÈes et des sorties, permettant le traitement de donnÈes.
Les donnÈes convergeant vers des entrÈes et divergeant vers des sorties sont des informatons comprÈhensibles par un Ítre humain. Par exemple, un paragraphe saisi au clavier, ou une page numÈrisÈe sont directement interprÈtables par l'homme, de mÍme que des paroles Èmises par l'intermÈdaire de moyens phoniques ou un document web affichÈ sur un moniteur. Par contre, ces informations sont converties dans un langage comprÈhensible par le matÈriel et en particulier le processeur ou unitÈ de traitement. En l'occurrence, ces informations sont des donnÈes binaires, soit une suite de bits dont chacun peut prendre la valeur 0 ou 1 (false ou true, faux ou vrai, fermÈ ou ouvert) que l'ensemble du systËme pÈriphÈrique convertit au grÈ des besoins.
La plus petite information binaire est un bit. Les bits sont regroupÈs dans des octets (bytes), soit des groupes de huit bits. Les octets constituent des mots de un, deux, quatre ou huit octets directement soumis au processeur. Un processeur 32 bits pourra traiter un mot de 64 bits en utilisant deux temps d'horloge. En effet, l'unitÈ de traitement synchronise ses opÈrations par rapport ý une horloge (quartz) envoyant des signaux ý intervalles rÈguliers, il s'agÓt en fait, de la frÈquence du processeur. Plus, cette frÈquence est ÈlevÈe, plus rapidement seront effectuÈs les calculs et les Èchanges d'informations entre le systËme pÈriphÈrique et l'unitÈ de traitement. DiffÈrentes mÈmoires sont mises ý la disposition du CPU afin de stocker les diffÈrentes informations relatives au fonctionnement du systËme informatique (ROM : Read Only Memory, mÈmoire permanente) et de conserver des informations provenant de diffÈrentes sources comme le systËme pÈriphÈrique ou le processeur lui-mÍme (RAM : Random Access Memory, mÈmoire volatile) d'accÈlÈrer le traitement des donnÈes (mÈmoire cache) et de charger des mots binaires avant traitement (registres intÈgrÈs au processeur).
Le CPU commande tout le systËme informatique via un circuit Èlectrique appelÈ bus systËme. Toutes les mÈmoires sont connectÈes ý ce bus possÈdant Ègalement une certaine frÈquence. L'ensemble des pÈriphÈrique est Ègalement reliÈ ý ce circuit par l'intermÈdiaire de dispositifs d'intÈgration appelÈs interfaces. Ces derniËres fonctionnent comme des mÈmoires pour le processeur, dans lesquelles il peut lire et Ècrire des donnÈes binaires.
Le CPU est capable de faire des opÈrations ÈlÈmentaires telles que l'addition, la soustraction, la multiplication, les dÈcalages, des opÈrations logiques ET, OU, NON, etc.. Lorsqu'un calcul est ÈffectuÈ par le processeur, plusieurs informations binaires lui sont d'abord transmises, comme des opÈrandes droite et gauche ainsi qu'une instruction d'addition (par exemple), puis en fonction de ces donnÈes, un rÈsultat est produit et est retournÈ ý l'utilisateur.
Toutes les opÈrations ÈlÈmentaires prÈcitÈes que le processeur est capable de faire, sont dÈsignÈes chacune par une information binaire spÈcifique stockÈe en mÈmoire centrale. Ces instructions constituent le langage machine, en quelque sorte le logiciel de programmation le plus prÙche du processeur. Chacune de ces instructions dÈclenche une commande de base du processeur comme dans l'exemple prÈcedent : rechercher des valeurs dans la mÈmoire pour charger des registres, puis additionner les deux registres et stocker le rÈsultat dans un autre registre avant utilisation.
Le langage machine n'est pas universel puisque des systËmes informatiques Macintosh ou PC (Personal Computer) ne gËre pas les instructions de la mÍme faÁon si bien que ces machines sont incompatibles entre elles ý moins de possÈder un Èmulateur manquant souvent de performances.
Le systËme d'exploitation (OS : Operating System) de tout systËme informatique s'appuie sur le langage machine pour accomplir la moindre de ses actions. L'OS est un logiciel chargÈ des opÈrations de bas niveau, c'est-ý-dire au plus prËs du matÈriel. Les donnÈes et les instructions sont dÈcomposÈes en unitÈ ÈlÈmentaires par le systËme d'exploitation avant de les soumettre ý l'unitÈ de traitement.
Il existe diffÈrents types d'OS sur le marchÈ comme DOS, Unix, Mac OS, Windows, OS/2 et Linux. Tous n'ont pas les mÍmes caractÈristiques, et ne sont pas tous employÈs dans les mÍmes domaines. Par exemple la famille Unix (AIX, Digital Unix, HP-UX, NetBSD, OpenBSD, SCO, Solaris, SunOS), sans conteste la plus mature, est utilisÈe dans le domaine des serveurs professionnels, Mac OS se positionne dans la sphËre de la PAO (Publication AssistÈe par Ordinateur), du graphisme ou du multimÈdia, et Windows s'Èparpillant dans tous les secteurs, Èquipe les particuliers comme les entreprises.
Les systËmes d'exploitation se dÈmarquent les uns des autres par certaines capacitÈs de fonctionnement interne de leur noyau (kernel). Par exemple, DOS est mono-utilisateur et monot‚che, la gamme des Windows XX destinÈe aux particuliers sont de types mono-utilisateur et multit‚ches, tandis qu'un Unix est multi-utilisateurs et multit‚ches. Les termes mono/multi-utilisateurs et mono/multit‚ches signifient respectivement que l'OS est capable d'accepter sur un mÍme SI un ou plusieurs utilisateurs et exÈcuter une ou plusieurs opÈrations simultanÈment. D'autre part, certains OS seront excellents dans des secteurs prÈcis car leur jeu d'instructions ÈlÈmentaires et leur architecture seront plus ou moins bien adaptÈs ý l'utilisation qui en sera faite.
Les interfaces utilisateurs selon les systËmes d'exploitation diffËrent entre eux. Acutellement, l'interface graphique utilisateur (GUI : Graphic User Interface) propose une ergonomie sans conteste efficace et conviviale. Quasiment tous les OS possËdent une inteface fenÍtrÈe pilotable ý la souris, permettant une navigation visuelle jusqu'au coeur du systËme. NÈanmoins, le mode console (ligne de commandes) des anciens Unix, DOS ou Linux demeurent encore aujourd'hui incontournable dans le secteur des rÈseaux et de la sÈcuritÈ informatique.
Divers programmes exÈcutables intÈgrÈs dans les systËmes d'exploitation permettent de configurer l'OS et le matÈriel (make, lsmod, menuconfig sous Linux, regedit, ipconfig sous Windows), de renseigner les utilisateurs (help, perfmon, setver sous Windows, history, diff, hdparm sous Linux, ) ou d'effectuer diverses t‚ches (edit, notepad, calc sous Windows, tar, tty, sh sous Linux).
Le systËme de fichiers est un composant extrÍmement important d'un OS puisque c'est ý lui que revient l'organistation des mÈmoires de masses. Dans un premier temps, les diffÈrents supports physiques tels que les disques durs ou les disquettes doivent subir un formatage spÈcifique dÈterminant la maniËre dont sera structurÈe les donnÈes binaires. Un disque dur sera ainsi divisÈ en secteurs, pistes et cylindres et une table d'allocation de fichiers situÈe en gÈnÈral dans le premier secteur servira ý repÈrer la localisation de chaque fichier et dossier.
Les fichiers sont une collection d'octets avec une structure particuliËre dÈpendant de son type (Feuille de calcul, document texte, image, programme source, exÈcutable, bibliothËque, etc.). Leur taille dÈpend de leur contenu, un fichier texte comprend des caractËres pesant chacun un octet, tandis qu'un exÈcutable peut contenir des instructions binaires pesant chacune de un ý huit octets. L'utilisation des fichiers passent obligatoirement par leur chargement en mÈmoire centrale (RAM). Seulement ý ce moment, ils pourront Ítre exÈcutÈs, consultÈs, ou encore modifiÈs. Les fichiers possÈdant en gÈnÈral un nom et une extension (identificateur.ext) sont regroupÈs dans des rÈpertoires, lesquels peuvent Ítre Ègalement placÈs dans d'autres rÈpertoires, formant ainsi une arborescence parfaitement connue par la table d'allocation. Tous les fichiers y compris les fichiers systËmes sensibles peuvent Ítre exploitables par des utilisateurs quelconques comme sous Windows 9X ou une segmentation des mÈmoires de masse est crÈÈe afin que les utilisateurs n'accËdent qu'aux fichiers autorisÈs par rapport ý leurs droits d'accËs ý l'image de Unix, Linux, Windows NT, 2000...
Un systËme informatique est une combinaison hautement interdÈpendante de matÈriels (processeur, pÈriphÈriques, etc.) et de logiciels (langage machine, systËme d'exploitation). Les OS proposent une interface en mode graphique ou parfois en ligne de commandes garantissant une comprÈhensibilitÈ entre l'utilisateur et la machine pour finalement exploiter au mieux l'ensemble des possiblitÈs qu'offrent un systËme informatique. A partir de l'interface utilisateur (UI : User Interface), le dÈveloppeur sera en mesure de programmer des applications qui viendront se greffer sur le SI et ainsi enrichir ce dernier d'une nouvelle couche applicative amÈliorant substantiellement l'UI.
SommaireUn systËme informatique est composÈ de plusieurs ÈlÈments matÈriels dont la synergie permet la manipulation ou la visualisation d'informations par rapport aux qualitÈs rÈceptives de l'homme.

Le processus de traitement de l'information semble transparente pour l'utilisateur car chaque action entrepris par l'utilisateur est transformÈe en une suite de donnÈes binaires que les diffÈrents composants seront alors capable de comprendre et d'interprÈter.
Le CPU ou l'unitÈ centrale de traitement (Central Processing Unit) est souvent connu sous le nom de processeur. Ce composant est au coeur du systËme informatique, quasiment toutes les informations binaires sont traitÈes par le processeur. Ce-dernier peut selon son architecture, faire des calculs sur des mots binaires de un octet (Intel 8088, Commodore, Apple II), deux octets (Intel 8086, i286), quatre octets (i386, AMD 386), huit octets (Intel Pentium, AMD Athlon, PowerPC) et plus pour les gros systËmes informatiques. La frÈquence et la densitÈ des composants ÈlÈmentaires sont Ègalement des caractËristiques importantes du processeur. La loi de Moore datant de 1966 (Gordon E.ÝMoore Ètait alors directeur de la recherche chez Fairchild) prÈvoyait un doublement des capacitÈs d'un processeur tous les dix-huit mois. Ainsi, en moins de deux dÈcennies, de 16 mÈgahertz avec 275 000 transistors pour l'intel i386 en 1985, les processeurs du millÈnaire comme l'Intel Pentium IV dispose de 42 millions de transistors pour une frÈquence de 1,5 gigahertz.
L'UAL ou UnitÈ ArithmÈtique et Logique (ALU : Arithmetic and Logical Unit) permet de faire des calculs mathÈmatiques tels que l'addition ou la multiplication, et des opÈrations boolÈennes telles que le ET, OU et NON. Ainsi, ý partir de chaque combinaison binaire (0 et 1) en entrÈe, l'UAL dÈtermine l'opÈration ý accomplir et produit un rÈsultat binaire en sortie.L'UAL fonctionne dans le mode combinatoire, ý l'aide de portes logiques.
Les registres sont des mÈmoires directement intÈgrÈes dans le processeur. Un registre permet de stocker une collection d'octets telle que le rÈsultat de la derniËre opÈration de l'UAL ou la donnÈe du prochain calcul. Le nombre de registres est limitÈ dans les processeurs, c'est pourquoi les informations binaires n'y font qu'un bref passage, le temps d'un ou plusieurs coups d'horloge.
PLusieurs registres spÈcifiques servent ý accueillir un certain type d'information binaires.
Les registres d'adresses permettent de rÈfÈrencer les adresses des programmes et des donnÈes dans les mÈmoires ROM, RAM et les interfaces. Ces adresses, en fait des nombres binaires, permettent au processeur de rÈcupÈrer les informations nÈcessaires ý un endroit prÈcis de la mÈmoire centrale (ROM et RAM) pour l'accomplissement de ses t‚ches.
Le registre d'instruction sert ý stocker l'information binaire dÈsignÈe par un code opÈration dÈdiÈe ý la rÈalisation d'un calcul arithmÈtique ou logique prÈdÈfini.
La PC (Partie Commande) pilote le processeur en opÈrant des instructions de branchement entre les registres. A chaque coups d'horloge, la PC ouvre et ferme des portes dans le but d'alimenter l'UAL en donnÈe et instruction et d'inderdire la collision d'information. Par cet intermÈdiaire, le processeur traite une opÈration ý la fois dans un intervalle donnÈe par l'horloge.
Le systËme informatique est entiËrement commandÈ par l'intermÈdaire de la PC. Les actions que ce composant est capable d'accomplir sont dÈsignÈes par des nombres binaires appelÈs codes opÈrations, lesquels forment le langage machine propre au fabricant du processeur. Un processeur Intel Pentium IV ne possËde pas le mÍme langage machine que son homologue Power Mac G4. Le langage comprÈhensible par l'homme au plus prËs du matÈriel s'appelle l'assembleur regroupant des commandes sous forme de mots clÈs de trois lettres maximum, comme MOV (dÈplacement vers un registre), ADD (addition), INC (incrÈmentation), etc.. Les programmes informatiques, ý commencer par le systËme d'explotation s'appuie sur cette forme primitive de langage pour exÈcuter des applications plus ou moins ÈvoluÈes.
Avant la livraison ý un client, le dÈveloppement d'un logiciel passe par plusieurs Ètapes dÈfinies au cours des deux derniËres dÈcennies :
* La recette est une vÈrification de conformitÈ du logiciel par rapport aux spÈcifications thÈoriques dÈfinies au dÈbut du projet, avant son dÈploiement final.
Le dÈveloppement d'un produit applicatif doit prendre en compte des risques inhÈrents ý cette activitÈ (dÈveloppement d'interfaces utilisateurs, ou de fonctions inappropriÈes, non-respect du cahier des charges, problËmes de performance, etc.) et ý l'Èvolution d'une entreprise (calendrier irrÈalisable, budget inadaptÈ, dÈfection des personnels, etc.).
C'est pourquoi, une sociÈtÈ de service en ingÈnierie informatique doit se conformer ý des rËgles intangibles de dÈveloppement d'application. A cet effet, il existe plusieurs modËles de cycle de vie d'un logiciel :
- Le modËle en cascade consiste en une succession de phases dont chacune est mÈthodiquement vÈrifiÈ avant de passer ý l'Ètape suivante :
- faisabilitÈ et analyse des besoins : validation,
- conception gÈnÈrale et dÈtaillÈe : vÈrification,
- intÈgration : tests d'intÈgration et tests d'acceptation,
- installation : tests du systËme.
- Le modËle en V repose sur une Ètroite interdÈpendance des Ètapes soumises ý une validation avant la prochaine Ètape et une vÈrification anticipatoire du produit final :
- spÈcification textuelle,
- conception gÈnÈrale,
- conception dÈtaillÈe,
- codage,
- tests unitaires,
- tests d'intÈgration,
- validation.
- Le modËle en spirale s'appuie sur une succession de cycles dont chacun se dÈroule en quatre phases :
- analyse initiale des besoins et des objectifs du cycle (solutions et contraintes) ou analyse ý partir du cycle prÈcËdent,
- Ètude des risques, Èvaluation des solutions de remplacement et Èventuellement conception,
- dÈveloppement et vÈrification de la solution rÈsultant de l'Ètape prÈcÈdente,
- examen du produit et projection vers le cycle suivant.
- Le modËle par incrÈment propose un dÈveloppement du logiciel par morceaux, lesquels sont livrÈs successivement au client, en venant se greffer ý un noyau logiciel.
Le modËle en V demeure actuellement le cycle de vie le plus connu et certainement le plus utilisÈ.

La premiËre Ètape, appelÈ spÈcification ou analyse des besoins, a pour but de dÈgager du cahier des charges, toutes les contraintes nÈcessaires ý l'Èlaboration du logiciel. Trois sortes de contraintes logicielles sont ý prendre en considÈration :
- Les contraintes externes dÈfinissent les caractÈristiques d'entrÈe/sortie du logiciel attendues par le client (donnÈes ý utiliser et ý afficher, les exigences ergonomiques, le parc informatique, etc.).
- Les contraintes fonctionnelles caractÈrisent le fonctionnement interne du logiciel, c'est-ý-dire, quels moyens seront mis en oeuvre pour traiter les informations d'entrÈe/sortie du logiciel (mÈthode de calcul, intervalle des donnÈes, etc.).
- Les contraintes de performances indiquent la vitesse d'exÈcution du logiciel ou de ses modules, la rÈsolution d'affichage, la prÈcision des donnÈes, etc..
Les documents produits (plan de dÈveloppement du logiciel, spÈcifications des besoins du logiciel et cahier de recette) au cours de cette phase permettent de passer ý l'Ètape suivante et Ègalement de prÈparer les vÈrifications de conformitÈ du logiciel.
Cette phase constitue environ 15 pourcents du temps total du cycle de dÈveloppement.
La conception gÈnÈrale (ou analyse organique gÈnÈrale)a pour objectif de dÈduire de la spÈcification, l'architecture du logiciel. Lors de cette phase, plusieurs solutions peuvent Ítre envisagÈes afin d'en Ètudier leur faisabilitÈ. A l'issue, un document de conception gÈnÈrale du logiciel est rÈalisÈ afin de dÈcrire la structure gÈnÈrale de l'alternative approuvÈe.
Lors de cette phase, il peut Ítre dÈcider de dÈcouper le logiciel en plusieurs modules distincts afin de les sous-traiter par plusieurs Èquipes de dÈveloppement. Un module possËde une interface permettant son intÈgration au logiciel global ou ý d'autres modules, et un corps pour son fonctionnement interne. Ils sont hiÈrarchisÈs de telle faÁon que des modules de bas niveau s'emboÓtent dans des modules intermÈdiaires, lesquels s'intËgrent ý un module de haut niveau (noyau logiciel).
Un autre dÈcoupage peut Ítre aussi utilisÈ pour scinder le logiciel en t‚ches distinctes. L'application contient alors plusieurs sous-ensembles ayant en charge des traitements spÈcifiques (t‚ches externes et t‚ches internes au logiciel), lesquels s'interconnectent entre eux
La phase de conception dÈtaillÈe (ou analyse organique dÈtaillÈe) en s'appuyant sur le document de conception gÈnÈrale, ÈnumËre l'architecture approfondie du logiciel jusqu'ý parvenir ý une description externe de chaque sous-ensemble et information utilisable dans le futur logiciel. A partir de cette Ètape, seront connus toutes les donnÈes (variables, constantes, attributs, champs, etc.) et fonctions (procÈdures, mÈthodes, etc.) de l'application vue de l'extÈrieur. Le logiciel peut Ítre entiËrement Ècrit en algorithme. Un langage de programmation est en gÈnÈral validÈ lors de cette phase. Un document de conception dÈtaillÈe, ainsi qu'un manuel d'utilisation sont ÈditÈs afin de respectivement de dÈcrire l'architecture dÈtaillÈe et la mise en oeuvre du logiciel. Les phases de conception doivent prendre environ 25 pourcents du temps total du cycle de dÈveloppement.
Des spÈcifications de tests d'intÈgration et unitaire sont Ègalement produites, ý l'issue des deux phases de conception. Elles permettront de confronter le fonctionnement de l'application ý son architecture gÈnÈrale et dÈtaillÈe.
Le codage consiste ý Ècrire avec un langage de programmation chacune des sous-programmes du logiciel. Le dÈveloppement peut Ítre confiÈ ý une seule personne dans le cas d'une application simple ou divisÈ entre plusieurs Èquipes de dÈveloppeurs dans le cas de projets importants. Cette phase durant environ 15 pourcents du temps total du cycle de vie se termine par la production d'un code source.
Les tests unitaires ont pour objectif de vÈrifier individuellement la conformitÈ de chaque ÈlÈment du logiciel (fonctions et variables) par rapport aux documents de conception dÈtaillÈe. Toutes les fonctionnalitÈs internes et externes de chaque sous-programme sont contrÙlÈes mÈthodiquement. En outre, un contrÙle des performances globales et locales est Ègalement entrepris. Cette phase consomme aux alentours de 5 pourcents du temps total du cycle de vie et se finalise par la rÈdaction des rÈsultats des tests.
La phase d'intÈgration permet de vÈrifier l'assemblage des diffÈrentes parties du logiciel. Les diffÈrents modules du logiciel sont successivement intÈgrÈs jusqu'ý aboutir ý la construction complËte, en respectant rigoureusement les spÈcifications des tests d'intÈgration. Chaque module doit parfaitement Ítre assimilÈ sans que le fonctionnement des modules prÈcÈdemment intÈgrÈs n'en soit aucunement affectÈ. Les rÈsultats de cette phase sont consignÈs dans un document des tests d'intÈgration. En gÈnÈral, une prÈsentation du logiciel est Ègalement rÈalisÈe. Les tests d'intÈgration reprÈsentent en moyenne 20 pourcents du temps total du cycle de dÈveloppement.
La derniËre phase a pour vocation de valider le logiciel dans son environnement extÈrieur. Le produit applicatif est mis en situation d'utilisation finale afin de vÈrifier s'il rÈpond parfaitement aux besoins ÈnoncÈs dans les spÈcifications textuelles (premiËre phase). Un document appelÈ rÈsultat de la recette est produit au terme de la phase de validation qui dure 10 pourcents du temps total du cycle de vie du dÈveloppement du logiciel.
La finalitÈ du cycle de vie en V consiste ý parvenir sans incident ý livrer un logiciel totalement conforme au cahier des charges. Lors de la phase de spÈcification textuelle, une nÈgociation avec le client permet d'affiner ou d'enrichir les besoins ý propos de certains points techniques omis ou obscurs dans le cahier des charges. Lorsque la spÈcification est validÈe, la suite du processus de dÈveloppement doit Ítre parfaitement encadrÈ, contrÙlÈ et approuvÈ de telle sorte qu'ý aucun moment, il ne soit possible de diverger des rËgles ÈnoncÈes lors de la premiËre phase.
LíalgËbre relationnelle a ÈtÈ introduite par M. CODD en 1970, pour formaliser les opÈrations sur les ensembles. Cíest gr‚ce ý ce systËme formel que líon peut dÈmontrer líÈquivalence des requÍtes sur des bases de donnÈes relationnelles, et que líon peut construire des optimiseurs de requÍtes.
Les opÈrations relationnelles permettent de combiner des ensembles de valeurs, appelÈes relations, entre eux dans le but díobtenir en fonction du type de líopÈration, un certain rÈsultat.
Plusieurs opÈrations relationnelles peuvent Ítre appliquÈes ý des tables de base de donnÈes dans des SGBDR. De telle opÈrations, appelÈes requÍtes, sont lancÈes par líintermÈdiaire du langage SQL afin díextraire díune ou plusieurs tables, une certaine combinaisons de colonnes (ou champs) et de lignes (ou uplets, tuples, enregistrements).
SommaireAvant d'aborder les opÈrations relationnelles ý proprement parler, il est nÈcessaire de dÈfinir le vocabulaire adaptÈ au modËle relationnel.
Une base de donnÈes comporte une ý plusieurs tables contenant diverses informations organisÈes par colonnes (ou champs) et lignes (ou enregistrements).
Dans le modËle relationnel, une table de donnÈes correspond ý une relation, dÈsignant un ensemble d'informations au sens mathÈmatique. La relation est-elle mÍme dÈcomposÈe en attributs et en n-uplets, correspondant respectivement aux colonnes et aux lignes des tables.
Les attributs d'une relation forment un schÈma, reprÈsentant la structure de cette relation. Le schÈma caractÈrise une relation ainsi que tous les n-uplets qui y sont contenus.
Un n-uplet correspond ý une combinaison de valeurs des n-attributs que possËdent la relation. Par exemple, si une relation possËde six attributs, alors cette relation sera composÈe d'un certain nombre de "six-uplets".
Les n-uplets doivent tous Ítre identifiables d'une maniËre unique. Pour assurer l'unicitÈ d'un n-uplet, il est nÈcessaire de dÈfinir dans une relation, une clÈ primaire. Cette derniËre, peut Ítre un attribut ou une combinaison d'attributs (clÈ primaire composite), produisant respectivement une certaine valeur ou un ensemble de valeurs qui doit impÈrativement Ítre unique, afin d'identifier prÈcisÈment un et un seul n-uplet dans la relation.
Les relations peuvent Ítre reliÈes ý d'autres relations par l'intermÈdiaire d'une liaison entre des clÈs identificatrices. Une relation peut contenir une clÈ ÈtrangËre faisant rÈfÈrence ý la clÈ primaire d'une seconde relation. De cette maniËre, il devient possible de crÈer, pour les attributs d'une relation, des domaines de valeurs contenus dans d'autres relations liÈes. Par exemple un attribut dÈnommÈ couleur pourrait ne contenir qu'un seul code couleur dÈfini dans une liste externe prÈdÈterminÈe.
|
|
|---|
Une clÈ primaire peut Ítre Ègalement une clÈ ÈtrangËre rÈfÈrenÁant une autre relation.
Les liaisons entre relations possËdent des cardinalitÈs reprÈsentant le nombre d'occurrences de valeurs uniques autorisÈes entre des attributs de mÍme domaine ou ayant le mÍme sens. En fait, il existe trois combinaisons gÈnÈriques de cardinalitÈs : Un ý Un, Un ý Plusieurs ou Plusieurs ý Plusieurs. La premiËre cardinalitÈ s'applique ý une clÈ primaire et la seconde ý une clÈ ÈtrangËre. De cette maniËre, il est possible de dÈfinir pour une relation son type de dÈpendance avec d'autres relations. Par exemple, un relation dÈnommÈe famille contient plusieurs personnes et ý l'inverse une personne ne peut appartenir qu'ý une et une seule famille (parentale).

Les conventions de prÈsentation dÈfinissent qu'une clÈ primaire doit Ítre soulignÈe et qu'une clÈ secondaire doit Ítre suivie d'un signe diËse '#' ou d'une Ètoile '*'. Dans les modËles d'analyse Merise ou UML (Unified Modeling Language), les cardinalitÈs Plusieurs peuvent Ítre symbolisÈes par une lettre 'n' ou parfois un signe infini, notamment dans le cas de Microsoft Access.
Líunion de deux relations possÈdant un schÈma identique produit une relation rÈsultante. Cette derniËre de mÍme schÈma que celles dont elle est issue contient líensemble des n-uplets appartenant ý chacune des deux relations ainsi que les uplets communs aux deux.
Formalisme : R = UNION(Ra, Rb) ou R = Ra U Rb
|
| ||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||
Langage SQL : SELECT * FROM Ra UNION SELECT * FROM Rb;
Líintersection de deux relations possÈdant un schÈma identique produit une relation rÈsultante. Cette derniËre de mÍme schÈma que celles dont elle est issue contient líensemble des n-uplets communs aux deux relations.
Formalisme : R = INTERSECTION(Ra, Rb)
|
| ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||
Langage SQL :
SELECT * FROM Ra
INTERSECT
SELECT * FROM Rb;
'ou
SELECT A, B, C FROM Ra
WHERE A IN (SELECT A FROM Rb)
AND B IN (SELECT B FROM Rb)
AND C IN (SELECT C FROM Rb) ;La diffÈrence entre deux relations possÈdant un schÈma identique produit une relation rÈsultante. Cette derniËre de mÍme schÈma que celles dont elle est issue contient líensemble des n-uplets appartenant ý la relation soustraite et n'appartenant pas ý l'autre relation.
Formalisme : R = DIFFERENCE(Ra, Rb) ou R = Ra - Rb
|
| ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||
Langage SQL :
SELECT * FROM Ra
EXCEPT
SELECT * FROM Rb;
'ou
SELECT A, B, C FROM Ra
WHERE A NOT IN (SELECT A FROM Rb)
AND B NOT IN (SELECT B FROM Rb)
AND C NOT IN (SELECT C FROM Rb);Le produit de deux relations possÈdant un schÈma quelconque produit une relation rÈsultante. Cette derniËre possËde les attributs des deux relations dont elle est issue, ainsi que toutes les combinaisons entre les n-uplets de chacune des relations prÈcitÈes.
Formalisme : R = PRODUIT(Ra, Rb) ou R = Ra x Rb
|
| ||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||
Langage SQL : SELECT * FROM Ra, Rb;
La projection ne s'applique qu'ý une seule relation en produisant une relation rÈsultante. Cette derniËre ne possËde que certains attributs dÈterminÈs de la relation dont elle est issue, et contient tous les n-uplets du ou des attributs projetÈs, de la relation prÈcitÈe ý l'exception des doublons. Cette opÈration de projection a pour but d'Èliminer des attributs d'une relation.
Formalisme : R = PROJECTION(Ra, Atribut1, ..., AttributN)
ou
R = PROJECTIONAtribut1, ..., AttributN(Ra)
|
|
|---|
Langage SQL : 'Avec doublons SELECT B FROM Ra; 'Sans doublons SELECT DISTINCT B FROM Ra; 'ou SELECT B FROM Ra GROUP BY B;
La sÈlection (ou restriction) ne s'applique qu'ý une seule relation en produisant une relation rÈsultante. Cette derniËre de mÍme schÈma de la relation dont elle est issue, ne contient que certains n-uplets correspondant ý une condition exprimÈes par l'intermÈdiaire d'opÈrateurs logiques (OU, ET, NON) et/ou arithmÈtiques (=, !=, <, >, <=, >=).
Formalisme : R = SELECTION(Ra, Attribut opÈrateur "Valeur")
ou
R = SELECTIONAttribut opÈrateur "Valeur"(Ra)
|
|
|---|
Langage SQL : SELECT * FROM Ra WHERE B = "b";
La jointure entre deux relations possÈdant un schÈma quelconque mais avec au moins un attribut dÈfini dans le mÍme domaine de valeurs, produit une relation rÈsultante. Cette derniËre comporte la totalitÈ des attributs de chacune des relations dont elle est issue, et contient la combinaison de tous les n-uplets des deux relations prÈcitÈes, correspondant ý la condition de jointure.
Cette condition peut tester l'ÈgalitÈ entre un ou plusieurs attributs toujours dÈfinis dans le mÍme domaine, c'est-ý-dire, dans un ensemble de valeurs autorisÈes pour chacun des attributs communs aux deux relations. Par ailleurs, les attributs comparÈs sur les deux relations peuvent ne pas avoir le mÍme nom.
Ainsi dans les thÈta-jointures, on distingue l'Èquijointure, vÈrifiant l'ÈgalitÈ des valeurs d'attributs, et d'autres vÈrifiant une comparaison de diffÈrence, d'infÈrioritÈ ou de supÈrioritÈ (!=, <, >, <=, >=).
Formalisme : R = JOINTURE(Ra, Rb, Ra.Attribut opÈrateur Rb.Attribut)
ou
R = JOINTURERa.Attribut opÈrateur Rb.Attribut(Ra, Rb)
|
| ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||
SommaireLangage SQL : SELECT a.A, a.B, a.C, b.D, b.E FROM Ra AS a, Rb AS b WHERE a.C = b.C;
La jointure naturelle est une Èquijointure dont la condition porte sur l'ÈgalitÈ de valeurs entre tous les attributs de mÍme nom, des relations concernÈes. Le schÈma de la relation rÈsultante correspond ý une concatÈnation de l'ensemble des attributs des deux relations dont elle est issue, autour du ou des attributs communs.
Formalisme : R = JOINTURE(Ra, Rb)
|
| ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||
Langage SQL : SELECT a.A, a.B, a.C, b.D FROM Ra AS a, Rb AS b WHERE a.B = b.B AND a.C = b.C;
L'auto jointure permet d'effectuer une opÈration de jointure rÈflexive sur une relation unique dÈdoublÈe. Le schÈma de la relation rÈsultante sera composÈ par une concatÈnation de tous les attributs des relations dont elle est issue.
Le langage SQL : SELECT * FROM Ra AS a, Ra AS b WHERE a.B = b.B;
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Les jointures externes sont utilisÈes pour afficher tous les n-uplets, y compris ceux n'ayant pas de correspondance dans l'une ou l'autre des relations concernÈes. Le schÈma de la nouvelle relation est composÈe de l'ensemble des attributs des relations dont elle est issue.
Les jointures externes peuvent Ítre appliquÈes en complet, ý droite ou ý gauche.
- Une jointure externe complËte provoque la crÈation d'une relation rÈsultante contenant tous les n-uplets, y compris ceux ne pouvant Ítre joints des relations impliquÈes.
- Une jointure externe ý gauche provoque la crÈation d'une relation rÈsultante contenant tous les n-uplets, y compris ceux ne pouvant Ítre joints de la relation placÈe ý gauche.
- Une jointure externe ý droite provoque la crÈation d'une relation rÈsultante contenant tous les n-uplets, y compris ceux ne pouvant Ítre joints de la relation placÈe ý droite.
Langage SQL :
SELECT * FROM Ra
{FULL | LEFT | RIGHT} OUTER JOIN Rb
ON Ra.B = Rb.BDans ce cas, Ra est la relation de gauche et Rb la relation de droite.
|
| ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||
Les fonctions d'agrÈgation calculent une rÈsultat ý partir des valeurs numÈriques d'un attribut d'une relation.
Ces fonctions sont des mots-clÈs SQL prÈdÈfinis et sont utilisÈes pour fournir des informations de synthËse, ý l'image d'une somme, d'une moyenne, d'un minimum et d'un maximum des valeurs d'un attribut ou encore d'un nombre de n-uplets.
SommaireUn dÈnombrement des n-uplets de regroupements d'une relation ou de la totalitÈ de cette derniËre s'effectue par l'intermÈdiaire d'une fonction d'agrÈgation, dÈnommÈe compte (count()).
Cette fonction compte le nombre d'occurrences pour une relation et Èventuellement un attribut donnÈs.
Syntaxe SQL : SELECT count(Champ | *) FROM Relation [ORDER BY Champ] [HAVING Champ = "valeur"];
|
|
|---|
Langage SQL : SELECT count(*) FROM Ra SELECT A, count(A) FROM Ra GROUP BY A;
Une somme d'un uplet de regroupements d'une relation ou de la totalitÈ de cette derniËre s'effectue par l'intermÈdiaire d'une fonction d'agrÈgation, dÈnommÈe somme (sum()).
Cette fonction effectue la somme des valeurs numÈriques pour un attribut d'une relation donnÈs.
Syntaxe SQL : SELECT sum(Champ) FROM Relation [ORDER BY Champ] [HAVING Champ = "valeur"];
|
|
|---|
Langage SQL : SELECT sum(C) AS Sc, sum(F) AS Sf FROM Ra SELECT A, sum(C) AS Sc FROM Ra GROUP BY A;
La moyenne des valeurs d'un attribut d'une relation est calculable par l'intermÈdiaire de la fonction de moyenne (avg()).
Cette fonction calcule une moyenne ý partir de la somme des valeurs d'un attribut spÈcifiÈ en argument et du nombre total d'occurrences pour l'attribut d'une relation ou Èventuellement de chaque groupe d'un autre attribut.
Syntaxe SQL : SELECT [champG, ]avg(Champ) FROM Relation [ORDER BY ChampG] [HAVING ChampG = "valeur"];
|
|
|---|
Langage SQL : SELECT avg(C) FROM Ra SELECT A, avg(C) FROM Ra GROUP BY A;
Le minimum et le maximum d'un attribut sont accessibles respectivement via des fonctions spÈcifiques d'extraction min() et max().
Ces fonctions dÈterminent les valeurs numÈriques minimum et maximum ý partir d'un attribut passÈ en argument.
Syntaxe SQL : SELECT [ChampG, ]min(Champ), max(Champ) FROM Relation [ORDER BY ChampG] [HAVING ChampG = "valeur"];
|
|
|---|
Langage SQL : SELECT min(C), max(C) FROM Ra SELECT A, min(C), max(C) FROM Ra GROUP BY A;