L'Altruiste : Le guide des langages Web
Le langage SQL
Le SQL est un langage de requête structuré (Structured Query Language) destiné à communiquer avec des bases de données relationnelles implémentées dans des SGBDR (Système de Gestion de Bases de Données Relationnelles) tels que Oracle, PostgreSQL, MySQL, SQL Server ou encore Paradox ou FoxPro.
Les bases de données relationnelles adoptent un modèle spécifique qui s'appuie sur l'algèbre relationnelle, laquelle a été introduite par M. CODD en 1970, afin de permettre la formalisation des opérations sur les ensembles.
Le langage SQL permet d'effectuer diverses opérations comme la création, l'extraction, la modification, la suppression, la fusion, etc., sur des collections de données, par l'intermédiaire d'instructions particulières appelées des commandes, souvent assistées d'ailleurs par des clauses ou des options.
La première mouture du langage SQL est apparu en 1979, puis sera standardisé à quatre reprises; en 1986 avec le SQL-ANSI (American National Standard Institute), en 1989 avec SQL-ISO (International Standard Application) et ANSI, en 1992 avec la seconde version du SQL-ISO et ANSI et enfin en 1999, pour établir la troisième version.
La dernière version, SQL 3, est composée de cinq parties distinctes :
- le cadre SQL énonçant les bases principales,
- les fondations SQL spécifiant la syntaxe et le fonctionnement,
- l'interface d'appel SQL définissant l'interface de programmation,
- les modules mémorisés persistants,
- les liaisons avec le langage hôte.
En outre, le standard SQL possède deux niveaux de compatiblité avec des systèmes de bases de données :
- le support principal, définissant les fondements du langage,
- le support optimisé, fournissant des améliorations.
Malgré l'existance d'un standard destiné à assurer un degré de compatibilité optimal entre les différents SGBDR, les éditeurs ont pour la plupart intégrés des adjuvants, soit des extensions propriétaires améliorant leur propre implémentation. L'ensemble de ce cours est évidemment tributaire des différences entre les différentes implémentations, c'est pourquoi, il faut indubitablement, consulter au moins deux sites de références sur le langage SQL :
Le SQL 3 sera certainement la dernière avancée avant le basculement dans un langage de requête orienté vers une plus grande coopération vers XML (eXtended Markup Language), le XQL (XML Query Language).
Les bases de données sont utilisées pour le stockage de diverses informations, ordonnées en de multiples unités hiérarchisées.
La structure atomique d'une base de données permet au développeur de la décomposer en plusieurs objets représentant chacun une de ses dimensions.
Ainsi, un objet principal base de données se divise en d'autres objets appelés tables, elles-mêmes scindées en objets colonne et ligne dont découlent par référence croisée, les valeurs.
Une base de données se compose, donc, d'une à plusieurs tables, dont chacune est identifiée par un nom.
Les tables d'une base de données sont, en principe, toutes reliées entre elles selon un schéma de relation.
Les tables contiennent un à plusieurs enregistrements, c'est-à-dire des lignes de données.
Chacune des tables d'une base de données se décompose en un à plusieurs champs appelés également colonnes.
| Table |
Champ_1
(col_1) |
Champ_2
(col_2) |
Champ_3
(col_3) |
Champ_4
(col_4) |
| Valeur |
Valeur |
Valeur |
Valeur |
| Valeur |
Valeur |
Valeur |
Valeur |
<----------------------- Enregistrement ---------------------->
( Ligne ) |
Ces colonnes sont représentées d'une part par un nom individuel servant à leur identification dans une table et d'autre part par un type de données pour le genre d'informations qu'elles comprennent comme du texte, des nombres, des dates et des heures ou encore des valeurs binaires (BLOB : Binary Large OBject) telles que des images.
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| NUMBER(10) |
VARCHAR(20) |
VARCHAR(20) |
NUMBER(5) |
Chaque enregistrement d'une table doit possèder une clé unique, utilisée pour les distinguer individuellement, à l'image d'un numéro de sécurité sociale pour chaque individu. Une colonne spécialement conçue à cet effet doit contenir ce genre d'informations où aucun doublon n'est permis. Cette colonne est appelée la clé primaire d'une table. L'indexation ainsi effectuée permet un accès rapide et sans équivoque à un enregistrement particulier d'une table.
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| 187 |
JANVIER |
Denis |
77870 |
| 1097 |
NAPOLI |
Victor |
75020 |
| 10852 |
ARCHI |
Bertrand |
93330 |
| 20140 |
MULLER |
Arthur |
75020 |
| 1654327 |
NAPOLI |
Julien |
75020 |
Le schéma de relation des tables précité, dépend étroitement des clés primaires affectées à chaque table de la base de données. Les tables sont reliées les unes aux autres par ces fameuses clés communes.
Par exemple, une table pourrait contenir deux colonnes, une appelée clé primaire et l'autre clé secondaire. Une seconde table contiendrait une clé primaire différente et une clé secondaire correspondant à la clé primaire de la première table. En conséquence, la seconde table pourra être mise en relation avec la première table par le biais de cette dernière clé strictement identique aux deux tables. il sera alors, possible de joindre les enregistrements connexes des deux tables entre eux.
La manipulation des données s'effectue par l'intermédiaire de requêtes regroupant plusieurs instructions SQL. Une requête précise est capable entre autres, d'accomplir des extractions, des ajouts, des mises à jour, des suppressions de données.
L'exécution de certaines requêtes sur des bases de données peut retourner des objets spécifiques, comme des vues ou des curseurs.
Une vue est une table virtuelle dont le contenu est déterminé par une requête. Une vue possède donc une structure identique à celle d'une table de base de données hormis que ses lignes et ses colonnes proviennent d'une à plusieurs tables indiquées dans la requête.
Un curseur représente la valeur en cours stockée en mémoire et résultant d'une requête appliquée sur une base de données. Un curseur peut contenir d'un à plusieurs enregistrements qui peuvent être accédés par des commandes SQL spécifiques.
SELECT * FROM Fiche_Personne WHERE Nom = "NAPOLI"
La requête retourne le résultat suivant :
| Curseur |
| id |
Nom |
Prenom |
CP |
| 1097 |
NAPOLI |
Victor |
75020 |
| 1654327 |
NAPOLI |
Julien |
75020 |
Un schéma est une collection d'objets comme des tables ou des vues, associée à un nom d'utilisateur de la base de données.
Dans la pratique, tout utilisateur créant un objet dans une base de données, engendre systématiquement un schéma, et partant, le nom de l'utilisateur devient le propriétaire de sa prôpre réalisation.
L'accés aux objets d'un schéma par un utilisateur quelconque, s'effectue par l'intermédiaire du nom du propriétaire associé à celui de l'objet.
nom_utilisateur.nom_objet
JJ_DUPUIS.TBL_Reference
Le propriétaire du schéma peut accéder à l'un de ses objets en l'appelant directement par son nom car le SGBDR recherche l'objet en priorité dans le schéma appartenant à l'utilisateur.
Chaque objet dans une base de données créé par leur utilisateur est ainsi clairement identifié par le couple propriétaire.objet, évitant d'une part d'éventuelles noms doubles et d'autre part des problèmes de sécurité.
En outre, il est possible de créer explicitement un schéma à l'aide de la commande CREATE SCHEMA.
CREATE SCHEMA AUTHORIZATION nom_schéma
{
instruction_CREATE_TABLE
|
instruction_CREATE_VIEW
|
instruction_GRANT
}
[
instructionN_CREATE_TABLE
|
instructionN_CREATE_VIEW
|
instructionN_GRANT
];
La commande CREATE SCHEMA propose un moyen de créer des tables, des vues et d'accorder des privilèges pour les objets à partir d'une unique instruction.
Exemple
CREATE SCHEMA AUTHORIZATION sh_personnel
CREATE TABLE ma_table
(identificateur INTEGER PRIMARY KEY,
nom VARCHAR(25),
prenom VARCHAR(25))
CREATE VIEW ma_vue
AS SELECT nom ||, prenom
FROM ma_table WHERE identificateur >= 120356
GRANT select ON ma_vue TO util; |
Il existe quatre types de données principaux dans le langage SQL.
Les nombres décimaux sont composés de deux parties distinctes; une avant le séparateur décimal et l'autre après. La longueur de cette dernière partie est fixée par un argument spécial, l'échelle, au sein des types de données numériques et la longueur totale par un autre argument, la précision.
La précision détermine la nombre maximum de chiffres d'une valeur numérique.
NUMERIC(Précision, Echelle)
NUMERIC(8, 0)
10 000 000
L'échelle d'une valeur numérique représente le nombre de chiffres de la partie décimale, soit celle à droite du séparateur décimal, le point ou la virgule selon les spécifications du système local.
742.23876 --> Echelle = 5
La valeur de l'échelle ne peut évidemment être égale ou supérieure à la valeur de la précision.
DECIMAL(Precision, Echelle)
DECIMAL(10, 5)
47 304.03274
DECIMAL(10, -7)
47 300
Les données alphanumériques peuvent être de longueur fixe ou variable.
- Dans le premier cas, il sera toujours demandé un argument indiquant la taille en octets de la chaîne de caractères.
CHARACTER(10)
La taille du texte est fixée à 10 caractères.
- Dans le second cas, le type devra être suivi d'une instruction spécifique, en l'occurrence VARYING permettant à un champ d'accepter des chaînes de caractères de taille variable. En outre, une taille maximum peut également être indiqué en argument.
CHARACTER VARYING(16384)
La taille du texte est limitée à 16 384 caractères.
Les valeurs numériques
| Type |
| Description |
NUMERIC(Précision, Echelle)
DECIMAL(Précision, Echelle)
DEC(Précision, Echelle) |
| représente des nombres décimaux avec une précision et une échelle à préciser en arguments (ex: P = 5 et E = 2 --> 01245.32). |
INTEGER
INT |
| représente des nombres entiers longs. |
| SMALLINT |
| représente des nombres entiers courts. |
| FLOAT(Précision, Echelle) |
| représente un nombre réel avec une précision et une échelle à préciser en arguments (ex FLOAT(10, 5) --> 1042103686.48523). |
| REAL(Echelle) |
| représente un nombre réel avec une simple précision. |
| DOUBLE PRECISION(Précision) |
| représente un nombre à virgule flotante en double précision. |
Les valeurs alphanumériques
| Type |
| Description |
CHARACTER(Longueur)
CHAR(Longueur) |
| représente une valeur alphanumérique de longueur fixe. |
CHARACTER VARYING(Longueur)
CHAR VARYING(Longueur)
VARCHAR(Longueur) |
| représente une valeur alphanumérique de longueur variable. |
NATIONAL CHARACTER
NATIONAL CHAR
NCHAR |
| représente une valeur alphanumérique de longueur fixe dépendant du jeu de caractères du pays. |
NATIONAL CHARACTER VARYING
NATIONAL CHAR VARYING
NCHAR VARYING |
| représente une valeur alphanumérique de longueur variable dépendant du jeu de caractères du pays. |
Les valeurs de date et d'heure
| Type |
| Description |
| DATE |
| représente une date (ex: 10/01/2002). |
| TIME |
| représente une heure (ex: 10:12:42) |
| TIMESTAMP |
| représente une valeur de date et d'heure combinées. |
| INTERVAL |
| représente un intervalle de date et de temps. |
Les valeurs binaires
| Type |
| Description |
| BIT(Longueur) |
| représente une chaîne de bit de longueur fixe. |
| BIT VARYING |
| représente une chaîne de bit de longueur variable. |
BINARY(Longueur)
BYTES(Longueur) |
| représente une valeur binaire d'une longueur précisée en argument. |
| IMAGE |
| représente une valeur binaire permettant de stocker des images. |
BOOLEAN
LOGICAL |
| représente une valeur de type booléenne qui cependant peut dans certain cas propre à SQL comporter trois états. |
| Type |
| Description |
| SQL_VARIANT |
| représente un variant SQL pouvant être de n'importe quel type, hormis les données ntext et text. |
| DATETIME |
| représente une valeur de date et d'heure comprises entre le 1er janvier 1753 et le 31 décembre 9999. |
| SMALLDATETIME |
| représente une valeur de date et d'heure courtes comprise entre le 1er janvier 1900 et le 6 juin 2079. |
| TIMESTAMP |
| indique la séquence de l'activité SQL Server sur une ligne, représentée sous la forme d'un nombre croissant au format binaire. |
| FLOAT |
| représente une valeur numérique flottante comprise entre -1.79E+308 et 1.79E+308. |
| REAL |
| représente une valeur numérique réelle comprise entre-3.40E+38 et 3.40E+38. |
| NUMERIC |
| représente une valeur numérique décimale comprise entre -1038+1 et 10381. |
| DECIMAL |
| représente une valeur numérique décimale comprise entre -1038+1 et 10381. |
| MONEY |
| représente une valeur numérique monétaire comprise entre -922 337 203 685 477,5808 et +922 337 203 685 477,5807. |
| SMALLMONEY |
| représente une valeur numérique monétaire courte comprise entre -214 748,3648 et +214 748,3647. |
| BIGINT |
| représente une valeur numérique entière comprise entre -9 223 372 036 854 775 808 et 9 223 372 036 854 775 807. |
| INT |
| représente une valeur numérique entière comprise entre -2 147 483 648 et 2 147 483 647. |
| SMALLINT |
| représente une valeur numérique entière comprise entre -32 768 et 32 767. |
| TINYINT |
| représente une valeur numérique entièr comprise entre 0 et 255. |
| BIT |
| représente une valeur binaire 1 ou 0. |
| NTEXT |
| représente une chaîne de caractères UNICODE-UCS-2 d'une longueur variable d'un maximum de 2 147 483 647 caractères. |
| NVARCHAR |
| représente une chaîne de caractères UNICODE-UCS-2 d'une longueur variable d'un maximum de 4 000 caractères. |
| NCHAR |
| représente une chaîne de caractères UNICODE-UCS-2 d'une longueur fixe d'un maximum de 4 000 caractères. |
| TEXT |
| représente une chaîne de caractères non-Unicode d'une longueur variable d'un maximum de 1 073 741 823 caractères. |
| VARCHAR(n) |
| représente une chaîne de caractères non-Unicode d'une longueur variable d'un maximum de 8 000 caractères. |
| CHAR(n) |
| représente une chaîne de caractères non-Unicode d'une longueur fixe d'un maximum de 8 000 caractères. |
| VARBINARY |
| représente une valeur binaire de taille variable d'un maximum de 8 000 octets. |
| BINARY |
| représente une valeur binaire de taille fixe d'un maximum de 8 000 octets. |
| IMAGE |
| représente une valeur binaire de taille variable d'un maximum de 2 147 483 647 octets. |
| UNIQUEIDENTIFIER |
| représente un identificateur unique global (GUID : Global Unique IDentifier). |
| CURSOR |
| représente la valeur contenu dans un curseur. |
| TABLE |
| représente une zone de stockage pour un ensemble de résultat dans l'éventualité d'un traitement ultérieur. |
| Type |
| Description |
| DATE |
| représente une valeur de date et d'heure comprises entre le 1er janvier 4712 BC et le 31 décembre 4712 AD. |
| TIME(Nb) |
| représente une valeur horaire avec des heures comprises entre 00 et 23, des minutes comprises entre 00 et 59 et des secondes entre 00 et 61.999. Le nombre Nb indique le nombre de chiffres dans les secondes, compris entre 0 et 6. |
| TIMESTAMP |
| utilisé pour le sockage, représente des valeurs de date : année, mois et jour, et des valeurs horaires : heure, minute et seconde. |
| NUMBER(p, e) |
| représente un nombre avec une précision p de 1 à 38 chiffres et un échelle e comprise dans l'intervalle de -84 à 127. |
| NUMERIC(p, e) |
| représente un nombre avec une précision et une échelle comprises entre 0 et 38. |
| DECIMAL(p, e) |
| représente un nombre décimal avec une certaine précision p et une certaine échelle e comprises entre 0 et 38. |
| REAL |
| représente un nombre à virgule flottante de simple précision, compris entre 10-38 et 1038. |
| FLOAT(p) |
| représente un nombre à virgule flottante avec une certaine précision, compris entre 10-308 et 10308. |
| DOUBLE PRECISION |
| représente un nombre à virgule flottante de double précision, compris entre 10-308 et 10308. |
| TINYINT |
| représente un nombre entier compris entre -128 et +127. |
| SMALLINT |
| représente une valeur numérique entière comprise entre -32 768 et 32 767. |
| INTEGER |
| représente un nombre entier compris entre -231 et 231. |
| BIGINT |
| représente un nombre entier avec une précision de 19 chiffres compris entre -1019 et 1019. |
| CHAR(Longueur) |
| représente une chaîne de caractères non-Unicode d'une longueur fixe d'un maximum de 4 000 caractères. L'instruction VARYING permet d'adopter une longueur variable à l'image de VARCHAR. |
VARCHAR(Nb_Octet)
VARCHAR2(Nb_Octet) |
| représente une chaîne de caractères d'une longueur variable maximum de 4 096 octets. |
| LONG VARCHAR(Nb_Octet) |
| représente une chaîne de caractères d'une longueur variable maximum de 2 gigaoctets. |
| CLOB |
| représente une grande chaîne de caractères UNICODE-UCS-2 d'une longueur variable d'un maximum de 2 gigaoctets. |
| BIT(Nb_Bit) |
| représente la valeur d'un bit, soit 0 ou 1. |
| RAW(Nb_Octet) |
| représente des données binaires bruts d'une taille maximum de 2 000 octets. |
| BINARY(Nb_Octet) |
| représente une valeur binaire de taille fixe d'un maximum de 4 096 octets |
| VARBINARY(Nb_Octet) |
| utilisé pour le stockage, représente une valeur binaire d'une longueur variable. |
| LONG VARBINARY(Nb_Octet) |
| utilisé pour le stockage, représente des données binaires bruts d'une taille varaiable maximum de 2 gigaoctets. |
| LONG |
| représente une chaîne de caractères d'une longueur variable d'une taille maximum de 2 gigaoctets. |
| LONG RAW(Nb_Octet) |
| représente des données binaires bruts d'une taille maximum de 2 gigaoctets. |
| BLOB |
| représente une grande valeur binaire d'une taille d'un maximum de 2 147 483 647 octets. |
| ROWID |
| représente une valeur hexadécimale de 16 octets représentant l'adresse unique d'une ligne de tableau. |
Le langage SQL permet de créer ses propres types de données par l'intermédiaire de l'instruction de CREATE TYPE voir de CREATE DOMAIN.
La création d'un type défini par l'utilisateur, produit un objet contenant un à plusieurs champs possédant chacun un type de données particulier.
CREATE TYPE Type_Utilisateur AS OBJECT
( Nom_Champ Type_Donnée,
...
Nom_ChampN Type_DonnéeN)
Cet objet ainsi créé devient utilisable dans une base de données par l'intermédaire d'une définition de type habituelle. Dans ce cas, le champ typé pourrait accepter plusieurs zones de types différents.
Nom_Champ Type_Utilisateur
CREATE TYPE Type_Personnel AS OBJECT
( Nom VARCHAR(20),
Prenom AS VARCHAR(20),
Naissance AS DATE )
CREATE TYPE Type_Coordonnee AS OBJECT
Adresse AS VARCHAR(50),
Ville AS VARCHAR(20),
CP AS DECIMAL(5, 0),
Tph AS DECIMAL(10, 0) )
Définition des types de données
CREATE TABLE Liste_Personnel
( IDPersonnel AS CHAR(10),
Employe Type_Personnel
Coordonnee Type_Coordonnee )
Un domaine doit être associé à un type de données puis être affecté à l'instar d'une définition de type à un champ de table.
CREATE DOMAIN Nom_Domaine AS Type_Donnée
CREATE DOMAIN DOM_IDPersonnel AS CHAR(10)
CREATE DOMAIN DOM_Nom AS VARCHAR(20)
CREATE DOMAIN DOM_Prenom AS VARCHAR(20)
CREATE DOMAIN DOM_Naissance AS DATE
CREATE DOMAIN DOM_Adresse AS VARCHAR(50)
CREATE DOMAIN DOM_CP AS DECIMAL(5, 0)
CREATE DOMAIN DOM_Ville AS VARCHAR(20)
CREATE DOMAIN DOM_Tph AS DECIMAL(10, 0)
Définition des types de données
CREATE TABLE Liste_Personnel
( ID DOM_IDPersonnel,
Nom DOM_Nom,
Prenom DOM_Prenom,
Date_Naissance DOM_Naissance,
Adresse DOM_Adresse,
Code_Postal DOM_CP,
Ville DOM_Ville,
Telephone DOM_Tph )
L'utilisation des types ou des domaines procure divers avantages, dont la facilité de modification globale des types de données dans l'ensemble de la base de données ou encore l'application de contraintes globales.
Les contraintes permettent d'indiquer les valeurs permises au sein des colonnes d'une table afin d'obtenir des caractéristiques spécifiques comme l'acceptation de valeurs nulles ou non-nulles, l'interdiction des doublons ainsi que l'affectation de clés primaire et étrangère.
Nom_Champ Type_Donnée Contrainte
Les Contraintes
| Contrainte |
| Description |
| Définition_Champ NULL |
| indique que le champ peut accepter des valeurs nulles. |
| Définition_Champ NOT NULL |
| indique que le champ n'accepte pas de valeurs nulles. |
| Définition_Champ UNIQUE |
| indique que les valeurs du champ ne peuvent comporter de doublons. |
Définition_Champ PRIMARY KEY
CONSTRAINT Nom_Contrainte
PRIMARY KEY ( Champ[s] ) |
| indique que le champ constitue la clé primaire de la table et que les doublons sont interdits. Dans la seconde expression, |
CONSTRAINT Nom_Contrainte FOREIGN KEY Champ
REFERENCES Table_Pointée(Champ_Clé_Primaire)
ON UPDATE { CASCADE | NO ACTION }
ON DELETE { CASCADE | NO ACTION } |
| indique que le champ constitue la clé étrangère référencée dans une autre table. Les clauses ON UPDATE et ON DELETE permettent (CASCADE) ou ne permettent pas (NO ACTION) respectivement la mise à jour ou la suppression de lignes de données mise en relation référentielles par la clés concordantes. |
La commmande CONSTRAINT permet de définir une contrainte sur une colonne lors de la création d'une table.
CONSTRAINT Définition_Contrainte
La définition de la contrainte contient une clause CHECK assurant l'intégrité du domaine en limitant les valeurs placées dans une colonne par l'intermédiaire de son expression.
CONSTRAINT Nom_Contrainte CHECK ( Expression )
L'expression de la clause CHECK peut être n'importe quelles conditions combinant notamment divers opérateurs logiques, de comparaisons, etc..
Les contraintes peuvent être modifiées ou supprimées par l'intermédiaire de la commande ALTER TABLE.
ALTER TABLE nom_table MODIFY CONSTRAINT nom_contrainte
ALTER TABLE nom_table DROP CONSTRAINT nom_contrainte
Exemple
CREATE TABLE TBL_Personne (
ID INTEGER PRIMARY KEY,
ID_Service INTEGER NOT NULL,
Nom VARCHAR(20) NOT NULL,
Prenom VARCHAR(20) NOT NULL,
Date_Naissance DATE NOT NULL,
Ville_Naissance VARCHAR(20) NOT NULL,
Situation_Familiale NOT NULL
CONSTRAINT ck_fam
CHECK(Situation_Familiale
IN ('Célibataire', 'Marié(e)', 'Divorcé(e)', 'Veuf(ve)', 'Concubinage')),
Adresse VARCHAR(50) NOT NULL,
Code_Postal CHAR(5) NOT NULL
CONSTRAINT ck_cp CHECK(Code_Postal LIKE ('[0-9][0-9][0-9][0-9][0-9]')),
Ville VARCHAR(20) NOT NULL,
Telephone CHAR(14) NULL
CONSTRAINT ck_tph
CHECK(Telephone
LIKE ('[0-9][0-9] [0-9][0-9] [0-9][0-9] [0-9][0-9] [0-9][0-9]')),
eMail VARCHAR(50) NOT NULL UNIQUE
CONSTRAINT ck_email CHECK(eMail LIKE ('%@%.%')),
CONSTRAINT CONST_ID FOREIGN KEY ID_Service
REFERENCES TABLE_Service(ID)
ON UPDATE CASCADE
ON DELETE CASCADE
) |
Une condition indique une combinaison d'une ou plusieurs expressions et d'opérateurs logiques afin d'effectuer certaines opérations sur une base de données.
Instruction Condition
Les conditions peuvent être appliquées dans un clause WHERE afin de sélectionner de supprimer ou de mettre à jour des éléments.
SELECT * FROM Table
WHERE eMail IS NULL AND NOT LIKE '%@%.%'
Certaines conditions comme avec les opérateurs logiques et de comparaison, sont utilisables également dans le cadre des contraintes.
CREATE TABLE TABLE_Personne
( ID INTEGER PRIMARY KEY,
Nom VARCHAR(20)
Prenom VARCHAR(20)
eMail VARCHAR(50)
CONSTRAINT Limite_ID
CHECK ( ID BETWEEN 10000 AND 19999 ) )
Exemple
CREATE TABLE TABLE_Personne (
ID INTEGER PRIMARY KEY,
Sexe VARCHAR(20) NOT NULL,
Nom VARCHAR(20) NOT NULL,
Prenom VARCHAR(20) NOT NULL,
eMail VARCHAR(50) NULL UNIQUE,
Telephone DECIMAL(10, 0) NULL,
ID_Service INTEGER NOT NULL,
CONSTRAINT Limite_ID
CHECK ( ID BETWEEN 10000 AND 19999 ) )
CONSTRAINT Limite_Sexe
CHECK ( Sexe = 'Masculin' OR 'Féminin' ) )
CONSTRAINT Limite_Nom
CHECK ( Nom IS LIKE %[-a-zA-Zàâäéèêëîïôöùûü]% )
CONSTRAINT Limite_Prenom
CHECK ( Nom IS LIKE %[-a-zA-Zàâäéèêëîïôöùûü]% )
CONSTRAINT Limite_eMail
CHECK ( eMail IS LIKE %@%.% )
CONSTRAINT Limite_TPH
CHECK ( Telephone BETWEEN 0000000000 AND 0999999999 )
CONSTRAINT fkID_Service FOREIGN KEY TABLE_Service ( ID_service )
REFERENCES TABLE_Service(ID) ON DELETE CASCADE
) |
Le langage SQL comme tout autre langage, nécessite divers opérateurs dans le but d'effectuer des manipulations sur des valeurs numériques, littérales ou encore logiques.
Les opérateurs permettent d'effectuer des calculs arithmétiques ou des opérations de concaténation à l'intérieur de requêtes SQL.
SELECT Prix - ((Prix * Reduction)/100), Produit
FROM Liste_Produit
Les opérateurs arithmétiques et de concaténations.
| Opérateur |
| Description |
| Expression1 + Expression2 |
| accomplit l'addition des deux expressions. |
| Expression1 - Expression2 |
| accomplit la soustraction des deux expressions. |
| Expression1 * Expression2 |
| accomplit la multiplication des deux expressions. |
| Expression1 / Expression2 |
| accomplit la division de la première expression par la seconde. |
| Expression1 % Expression2 |
| accomplit le modulo des deux expressions. |
| Expression1 || Expression2 |
| accomplit la concaténation de deux expressions. Le signe plus + est utilisé par SQL Server et || par Oracle. |
Exemple
--Pour Oracle
SELECT ID, Designation, Quantite, Prix * Quantite FROM Vente
WHERE Date_Commande >= SYSDATE - 7
--Pour SQL Server
SELECT ID, Designation, Quantite, Prix * Quantite FROM Vente
WHERE Date_Commande >= DATEDIFF(Day, 7, GETDATE())
-- Retourne les champs dont le prix total de
-- la commande relatifs au sept derniers jours.
--Pour Oracle
CREATE OR REPLACE VIEW vue_personne AS
SELECT nom || ' ' || prenom, adresse, code_postal, ville
from personne
--Pour SQL Server
CREATE OR REPLACE VIEW vue_personne AS
SELECT nom + ' ' + prenom, adresse, code_postal, ville
from personne |
Les opérateurs de comparaison permettent une mise en correspondance de deux expressions retournant une valeur booléenne True ou False.
SELECT *
FROM nom_table
WHERE expression Opérateur expression2
Si la première expression correspond en fonction de l'opérateur à la seconde expression, la comparaison retourne la valeur True et sinon, la valeur est False.
Les opérateurs de comparaison
| Opérateur |
| Description |
| Expression1 = Expression2 |
| vérifie l'égalité entre les deux expressions. |
| Expression1 { != | <> | ^= } Expression2 |
| vérifie la différence entre les deux expressions. |
| Expression1 > Expression2 |
| vérifie si la première expression est supérieure à la seconde. |
| Expression1 >= Expression2 |
| vérifie si la première expression est supérieure ou égale à la seconde. |
| Expression1 !> Expression2 |
| vérifie si la première expression n'est pas supérieure à la seconde. |
| Expression1 < Expression2 |
| vérifie si la première expression est inférieure à la seconde. |
| Expression1 <= Expression2 |
| vérifie si la première expression est inférieure ou égale à la seconde. |
| Expression1 !< Expression2 |
| vérifie si la première expression n'est pas inférieure à la seconde. |
Exemple
--Pour Oracle
SELECT ID, Designation, Quantite, Prix * Quantite FROM Vente
WHERE Date_Commande >= SYSDATE - 7
--Pour SQL Server
SELECT ID, Designation, Quantite, Prix * Quantite FROM Vente
WHERE Date_Commande >= DATEDIFF(Day, 7, GETDATE())
-- Retourne les champs dont le prix total de
-- la commande relatifs au sept derniers jours.
SELECT * FROM personne
WHERE code_postal < 33000 AND code_postal > 33999
--Pour SQL Server
SELECT * FROM personne
WHERE ville <> 'Paris'
--Pour Oracle
SELECT * FROM personne
WHERE ville != 'Paris'; |
Les opérateurs conjonctifs soit AND et OR, permettent de combiner plusieurs conditions.
condition AND | OR condition2 AND | OR conditionN
Les opérateurs conjonctifs
| Opérateur |
| Description |
| Expression1 AND Expression2 |
| retourne True si les deux expressions sont True. |
| Expression1 OR Expression2 |
| retourne True si l'une ou/et l'autre des expressions est True. |
| NOT Expression |
| retourne True si l'expression est fausse. |
Exemple
SELECT * FROM tbl_produit
WHERE prix <= 2000 AND prix >= 800;
INSERT INTO tbl_produit
SELECT * FROM vue_nouveau_produit
WHERE categorie = 'hygiène'
OR ( categorie = 'hi-fi et vidéo' AND prix <= 2000 )
SELECT * FROM personne
WHERE nom LIKE 'A%' AND nom NOT IN ('Aubert', 'Axelis')
UNION
SELECT * FROM employe
WHERE nom LIKE 'A%' OR nom LIKE 'B%'
SELECT titre, genre, realisateur, acteurs FROM films
WHERE annee = (SELECT annee FROM films WHERE titre = 'Terminator')
AND
genre = (SELECT genre FROM films WHERE titre = 'Terminator') |
Les opérateurs logiques permettent d'effectuer des comparaisons sur des expressions SQL.
expression Opérateur [ expression2 ]
A l'instar des opérateur de comparaison symboliques, les opérateurs logiques provoquent le retour d'une valeur booléenne True ou False.
Souvent, les opérateurs logiques ne comparent pas deux expressions, mais une seule par rapport à une valeur déterminée soit par le type de l'opérateur comme IS NULL, soit par un modèle passé en paramètre comme pour liKE.
Les opérateurs logiques
| Opérateur |
| Description |
| Expression1 { =, !=, >, <, <=, >=, !<, !> } ALL (Expression2) |
| retourne True si la comparaison entre les expressions Expression1 et Expression2 est True sur toutes les paires (valeur_Expression1, valeur_Expression2). |
| Expression1 { =, !=, >, <, <=, >=, !<, !> } ANY | SOME (Expression2) |
| retourne True si la comparaison entre les expressions Expression1 et Expression2 est True sur quelques paires (valeur_Expression1, valeur_Expression2). |
Expression_Test [ NOT ] BETWEEN
Expression_Début AND Expression_Fin = True | False |
| définit un intervalle sur lequel la recherche doit être appliquée. |
| EXISTS (Sous-Requête) |
| retourne True si l'enregistrement pointé par la sous-requête existe. |
| Expression_Test [ NOT ] IN ( Sous-Requête | Expression ) |
| retourne True si l'expression correspond ou ne correspond pas (NOT) à une des valeurs pointées par la sous-requête ou l'expression. |
| Expression IS [NOT] NULL |
| indique si la valeur est nulle ou non-nulle (NOT). |
| Expression IS [ NOT ] OF Type_Données |
| retourne True si l'expression possède ou ne possède pas (NOT) le type de donnée indiqué. |
| Expression [ NOT ] LIKE Modèle [ ESCAPE Caractère_Echappement ] |
| retourne True si le modèle correspond à l'expression. Le modèle peut comporter des caractères génériques % (n caractères), _ (un caractère), [Caractères] (ex. : [a-z], [abc]) ou [^Caractères] (ex. : [^a-z], [^xzk]) représentant respectivement une chaîne de zéro à plusieurs caractères, n'importe quels caractères, l'inclusion ou l'exclusion d'un à plusieurs caractères. Le caractère d'échappement permet d'inclure un caractère générique précité dans la mise en correspondance. |
| NOT (Expression) |
| retourne la valeur booléenne inverse de l'expression. |
| UNIQUE (Expression) |
| retourne la valeur booléenne True si l'expression ne possède pas de doublons. |
Exemple
SELECT * FROM tbl_personnel
WHERE age BETWEEN 25 AND 35
SELECT * FROM tbl_personnel
WHERE email IS NOT NULL
SELECT num_secu_soc FROM tbl_personnel
WHERE nom LIKE 'M%'
SELECT nom_variable FROM application
WHERE nom_variable LIKE 'var\_%' ESCAPE '\';
/* introduit le caractère d'échappement '\'
afin de rechercher des valeurs de champs
avec le caractère réservé '_'
SELECT nom, prenom, adresse, code_postal FROM personne AS p
WHERE identificateur EXISTS (SELECT num_emp FROM employes)
AND
75 = ALL (SELECT dpt FROM employes WHERE num_emp = p.identificateur)
ORDER BY nom, prenom
SELECT titre, genre, realisateur FROM films AS f
WHERE 'Al Pacino' = ANY (SELECT nom FROM acteurs WHERE id_film = f.id_film)
SELECT * FROM personne
WHERE id_personne IN (SELECT id_client FROM clients) |
Les opérateurs d'ensemble combinent le résultat de deux requêtes à l'intérieur d'un seul résultat. Les requêtes contenant de tels opérateurs sont appelées des requêtes composées.
Les opérateurs d'ensemble
| Opérateur |
| Description |
| Requête1 UNION Requête2 |
| retourne toutes les lignes sélectionnées par l'une et l'autre des requêtes. |
| Requête1 UNION ALL Requête2 |
| retourne toutes les lignes sélectionnées par l'une et l'autre des requêtes en incluant tous les doubles. |
| Requête1 INTERSECT Requête2 |
| retourne les lignes distinctes sélectionnées par les deux requêtes. |
| Requête1 MINUS | EXCEPT Requête2 |
| retourne les lignes distinctes sélectionnées par la première requête mais pas par la seconde. |
Exemple
SELECT num_Produit, Designation, Statut FROM TBL_Vente
UNION
SELECT num_Produit, Designation, Statut FROM TBL_Stock;
SELECT * FROM tbl_personnel
UNION ALL
SELECT * FROM vue_candidat_recu;
SELECT titre FROM films
INTERSECT
SELECT film FROM stock;
-- est équivalent à
SELECT titre FROM films
WHERE titre IN (SELECT film FROM stock);
SELECT nom, prenom FROM personne
MINUS
SELECT nom, prenom FROM clients;
-- est équivalent à
SELECT nom, prenom FROM personne
WHERE nom NOT IN (SELECT nom FROM clients)
AND prenom NOT IN (SELECT prenom FROM clients); |
Les commandes SQL se divisent en quatre catégories principales pour la définition, la manipulation, l'interrogation et le contrôle des données.
Le langage de définition propose des commandes de création (CREATE), suppression (DROP) et modification (ALTER) de tables, d'index, de contraintes, etc...
Le langage de Manipulation permet d'insérer (INSERT), de mettre à jour (UPDATE) des enregistrements, de supprimer (DELETE) des données, mais également de manipuler des curseurs (declare, OPEN, FETCH, CLOSE) au sein d'une base de données relationnelles.
Le langage de requête fournit une commande de sélection d'enregistrements (select) qui avec ses très nombreuses clauses et options offrent un support d'interrogation des bases de données très puissant et complet.
Le langage de contrôle est utilisé pour la gestion des droits d'accès aux utilisateurs en attribuant (GRANT) ou révoquant (REVOKE) des privilèges.
Il existe de nombreuses autres catégories de commandes comme celles explicitées ci-dessous.
Les commandes d'administration de données sont utilisées pour la réalisation d'audits et d'analyses d'opérations sur des bases de données.
Les commandes transactionnelles permettant de gérer les transactions de base de données. Il s'agît de notamment de COMMIT, ROLLBACK, SAVEPOINT et SET TRANSACTION.
Les commandes DDL (Data Defintion Language) définissant la structure d'une base de données, permet la création, la modification ou la suppression de divers objets tels qu'une table, une vue ou encore un index.
En premier lieu, si aucune base de données existe, il faut alors en créer une par l'intermédiaire de la commande CREATE DATABASE.
CREATE DATABASE nom_base_donnees;
Le nom d'une base de données ne doit pas excéder 128 caractères, lesquels peuvent être des lettres majuscules ([A-Z]) et minuscules ([a-z]) ainsi que des chiffres ([0-9]) et le caractère souligné ('_').
La connexion et la déconnexion à une base de données s'effectue respectivement par le truchement de la commande CONNECT et DISCONNECT.
CONNECT TO {DEFAULT | nom_serveur [AS alias_serveur ]
[USER nom_utilisateur] };
CONNECT TO laltruiste AS lal USER u_pascal_e
A la suite de l'exécution de cette commande, le mot de passe associé au nom d'utilisateur sera requis pour valider la connexion au serveur de bases de données.
Certains SGBDR comprenant une interface graphique, accomplissent une connexion au serveur en passant par une boîte de dialogue spécifique.
La commande CREATE TABLE permet de créer une table avec des colonnes d'un type de données spécifiés.
CREATE TABLE nom_table
(
nom_col type [ NULL | NOT NULL | PRIMARY KEY | UNIQUE ],
[ nom_colN type [ NULL | NOT NULL | PRIMARY KEY | UNIQUE ] ]
); |
Avant d'exécuter une telle commande, il est nécessaire de rassembler certains éléments indispensables.
Un nom de table unique doit être précisé afin de l'identifier dans la base de données.
Pour chaque colonne à créer à l'intérieur de la table, il faut spécifier des noms de colonnes distincts.
Chaque colonne nécessitant un type de donnée, il faut indiquer le type de données à assigner à chacune des colonnes à créer.
Toute table nécessitant une colonne faisant office de clé primaire, il faut impérativement en déterminer une avec une contrainte d'unicité UNIQUE.
Des contraintes peuvent être également spécifier pour les valeurs d'une colonne lors de la création de la table.
| Contrainte |
Description |
| NULL |
indique que la colonne peut contenir des valeurs nulles. |
| NOT NULL |
indique que la colonne ne peut contenir de valeurs nulles. |
| PRIMARY KEY |
indique que la colonne constitue la clé primaire de la table. |
| UNIQUE |
impose que chaque valeur de la colonne doit être unique. |
Plus précisément, les contraintes peuvent être appliquées au moyen de la clause CONSTRAINT.
nom_colonne type
[ CONSTRAINT constraint_name ]
{ [ NULL | NOT NULL ]
| [ { PRIMARY KEY | UNIQUE } ]
| [ [ FOREIGN KEY ]
REFERENCES table_référence [ ( colonne_référence ) ]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ]
]
| [ CHECK ( expression_logique ) ]
} [ ,...n ]
Une clé étrangère sur une colonne est déclarée par l'intermédiaire de FOREIGN KEY qui pointe la clé primaire de la table de référence. Ainsi, les tables mises en jeu tissent des liens d'intégrité référentielle entre elles. D'ailleurs, les éventuelles modifications (DELETE ou UPDATE) sur la table créée peuvent être appliquées en cascade (CASCADE), c'est-à-dire sur chacune des tables liées, ou à elle seule (NO ACTION).
Une table peut être créée à partir d'une autre table mais également d'une vue.
CREATE TABLE nom_table AS
SELECT nom_colonne,...,nom_colonneN
FROM nom_table | nom_vue
WHERE nom_colonne = 'valeur';
Exemple
CREATE TABLE "Fiche_Personne"
(ID NUMBER(8) UNIQUE,
Sexe VARCHAR(50) NOT NULL,
Nom VARCHAR(50) NOT NULL,
Prenom VARCHAR(50) NOT NULL,
Snd_Prenom VARCHAR(50) NULL,
Adresse VARCHAR(100) NOT NULL,
Code_Postal NUMBER(5) NOT NULL,
Ville VARCHAR(30) NOT NULL,
Telephone NUMBER(10) NULL,
eMail VARCHAR(30) NULL)
Engendre la création de la table ci-dessous : |
| Fiche_Personne |
| id |
Sexe |
Nom |
Prenom |
Snd_
Prenom |
Adresse |
CP |
Ville |
Telephone |
eMail |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
La commande ALTER TABLE est une requête permettant la modification d'une table en ajoutant, en supprimant ou en changeant les colonnes, leur définition ou les contraintes.
Syntaxe pour Oracle
ALTER TABLE Nom_Table
|
{ MODIFY CONSTRAINT nom_contrainte définition_contrainte
|
DROP
{ PRIMARY KEY | UNIQUE ( nom_colonne [, nom_colonneN] ) }
| CONSTRAINT nom_contrainte
}
|
{ ADD nom_colonne type_donnée [, nom_colonneN type_donnée ]
| MODIFY ( nom_colonne [type_donnée] [ définition_contrainte ]
[, nom_colonneN [type_donnée] [ définition_contrainte ] ]
| DROP [ COLUMN ]
nom_colonne | ( nom_colonne [, nom_colonneN ] )
[ CASCADE CONSTRAINT ] | INVALIDATE
}
Syntaxe pour SQL Server
ALTER TABLE table
{ [ ALTER COLUMN nom_colonne nouveau_type ]
| ADD
{ [ nom_colonne nouveau_type ]
| nom_colonne AS expression_colonne_calculée
} [ ,...n ]
| [ WITH CHECK | WITH NOCHECK ] ADD
{ définition_contrainte } [ ,...n ]
| DROP
{ [ CONSTRAINT ] nom_contrainte
| COLUMN nom_colonne } [ ,...n ]
| { CHECK | NOCHECK } CONSTRAINT
{ ALL | nom_contrainte [ ,...n ] }
La commande ALTER TABLE est très complète puisqu'elle permet :
- de modifier le type d'une colonne (ALTER | MODIFY COLUMN),
- d'ajouter de nouvelles colonnes (ADD nom_colonne),
- d'ajouter de nouvelles conraintes (ADD définition_contrainte) avec la clause CONSTRAINT précitée et indique si les données de la table doivent être ou ne pas être vérifiées (WITH CHECK | WITH NOCHECK) par rapport à une contrainte FOREIGN KEY ou CHECK nouvellement ajoutée,
- de supprimer des colonnes (DROP COLUMN),
- de supprimer des contraintes (DROP CONSTRAINT),
- d'activer (CHECK) ou de désactiver (NOCHECK) toutes les contraintes (ALL) ou certaines.
Exemple
ALTER TABLE tbl_produit ADD CONSTRAINT chk_code
CHECK (num <= 100)
DISABLE CONSTRAINT chk_code;
CREATE TABLE tbl_produit ( num INTEGER PRIMARY KEY)
GO
ALTER TABLE tbl_produit
ADD designation VARCHAR(50) NULL,
description VARCHAR(255) NULL,
code_magasin VARCHAR(12) UNIQUE,
prix REAL NOT NULL
GO
ALTER TABLE tbl_produit
MODIFY CONSTRAINT chk_code
CHK ( num >= 0 AND code <= 1000000000 )
ENABLE CONSTRAINT chk_code;
ALTER TABLE tbl_produit
DROP COLUMN code_magasin
GO
ALTER TABLE tbl_produit
DROP PRIMARY KEY
ALTER TABLE tbl_produit
ALTER COLUMN prix DECIMAL(7, 2)
GO |
Les exemples terminés par l'instruction GO sont écrits sous SQL Server, les autres pour Oracle.
La commande DROP TABLE est une requête permettant la suppression compléte d'une table.
DROP TABLE Nom_Table [RESTRICT | CASCADE]
Les deux clauses ne sont utilisables que sous Oracle.
La clause RESTRICT restreint la suppression aux enregistrements de la seule table et retourne une erreur si la table est référencée par une vue ou une contrainte.
La clause CASCADE provoque la suppression de la table et de toutes ses références.
Subséquemment à l'exécution d'une telle commande, plus aucune requête ne pourra être appliquée sur cette table.
Exemple
DROP TABLE Fiche
DROP TABLE tbl_candidat_recu CASCADE
Dans l'exemple ci-dessus, la table Fiche d'une quelconque base de données est totalement détruite.
La commande TRUNCATE TABLE est une requête permettant la destruction complète des données contenues dans une table.
Contrairement à la commande DROP TABLE, TRUNCATE TABLE conserve le schéma de relation de la table concernée, ainsi, celle-ci reste disponible dans la base de donnée pour de futures opérations.
TRUNCATE TABLE Nom_Table
Subséquemment à l'exécution d'une telle commande, la table ne contiendra plus aucune donnée.
Exemple
TRUNCATE TABLE Fiche
Dans l'exemple ci-dessus, la table Fiche d'une quelconque base de données subit essentiellement la destruction de toutes ses données. La structure de la table Fiche reste en place avec son schéma relationnel.
La commande CREATE INDEX permet de créer un index référençant les emplacements de chaque valeur d'une colonne.
CREATE INDEX nom_index ON nom_table ASC | DESC
Un index stocké séparément de la table, est un ensemble de pointeurs désignant chaque numéro de lignes associées aux données d'une colonne.
| Donnée |
Position |
| CAMPUSPRESS |
4 |
| EYROLLES |
3 |
| ENI |
5 |
| MICROSOFT PRESS |
7 |
| O'REILLY |
1 |
| O'REILLY |
2 |
| WROX PRESS |
6 |
L'indexation terminée, les données seront rangées selon un ordre ascendant ASC ou descendant DESC permettant un accès plus rapide aux emplacements des données dans la table concernée.
Un index n'est vraiment utile que pour des tables de grande dimension, afin d'éviter un balayage complet des lignes pour trouver une information.
En outre, l'index consomme un espace mémoire considérable puisqu'il est aussi important que celui de la table elle-même.
Une indexation peut s'appliquer sur une ou plusieurs colonnes.
Toutefois, un index sur une seule colonne reste le plus simple, et partant le plus efficace si la colonne concernée est sollicitée très régulièrement.
CREATE INDEX nom_index ON nom_table(nom_colonne)
Un index sur plusieurs colonnes est utilisable sur un ensemble de colonnes souvent employées dans des clauses conditionnelles WHERE. Dans ce cas, la
CREATE INDEX nom_index
ON nom_table(nom_colonne, ..., nom_colonneN)
Les index peuvent être supprimés par l'intermédiaire de l'instruction DROP INDEX.
DROP INDEX nom_index
Exemple
CREATE INDEX idx_personnel
ON tbl_personnel (num_secu_soc)
CREATE INDEX idx_personnel
ON tbl_personnel (nom, prenom) |
La commande CREATE VIEW permet de créer une vue, soit une table virtuelle produite par une requête de sélection.
Une vue contient donc un jeu d'enregistrements constitué par une requête SELECT prédéfinie appliquée à une ou plusieurs tables d'une base de données.
A la différence d'une table, une vue ne consomme pas d'espace de stockage physique mais conserve des propriétés semblables dans la mesure ou toutes les opérations de sélection, d'insertion, de mise à jour ou encore de suppression de lignes de données avec néanmoins quelques restrictions comme l'interdiction de modification d'une vue multitables.
Les vues peuvent servir à recueillir des données régulièrement consultées et mises à jour.
Les vues sont souvent employées pour des raisons de sécurité. A l'aide de cet outil, il devient possible de ne montrer qu'une partie des données d'une table et ainsi, cacher des informations confidentielles.
Le créateur de la vue en détient la propriété et les privilèges afférents à l'instar d'une table. En conséquence, le propriétaire de la vue peut accorder des droits aux différents utilisateurs de la base de données.
Subséquemment à sa création, une vue peut être utilisée de la même façon qu'une table. Des requêtes de sélection ou de manipulation de données peuvent être appliquées à la vue.
Création d'une vue sous SQL Server
CREATE VIEW [ nom_base . ] [ propriétaire . ] nom_vue
[ ( nom_colonne [ ,...n ] ) ]
[ WITH { ENCRYPTION | SCHEMABINDING | VIEW_METADATA } [ ,...n ] ]
AS instruction_selection... [ WITH CHECK OPTION ] |
La clause WITH ENCRYPTION indique que SQL Server crypte les colonnes des tables systèmes contenant le texte de l'instruction CREATE VIEW.
La clause WITH SCHEMABINDING implique que la requête de sélection doit contenir des noms sous la forme propriétaire.objet pour des tables, des vues ou des fonctions référencées.
La clause WITH VIEW_METADATA indique que SQL Server renvoie aux interfaces de programmation d'applications DBLIB, ODBC et OLE DB les informations de métadonnées sur la vue, au lieu des tables de la base de données, lorsque des métadonnées en mode lecture sont sollicitées pour une requête qui fait référence à la vue.
La clause WITH CHECK OPTION garantit que l'ensemble des instructions de modification exécutées sur la vue respectent le critère défini dans la requête de sélection.
Création d'une vue sous Oracle
CREATE [ OR REPLACE ] [ FORCE | NOFORCE ] VIEW [ propriétaire . ] nom_vue
(nom_colonne,...,nom_colonneN)
AS instruction_sélection...;
[WITH CHECK OPTION
[CONSTRAINT constraint]] |
L'instruction OR REPLACE crée à nouveau la vue si elle existe déjà.
Les clauses FORCE et NOFORCE indiquent respectivement que :
- la vue est créée sans se soucier de l'existence des tables qu'elle référence ou des privilèges adéquats sur les tables,
- la vue est créée seulement si les tables existent et si les permissions requises sont données.
La clause WITH CHECK OPTION limite les insertions et les mises à jour exécutées par l'intermédiaire de la vue.
La clause CONSTRAINT est un nom optionnel donné à la contrainte WITH CHECK OPTION.
Les vues peuvent être créées à partir d'autres vues. Pour cela il suffit de référencer les vues dans la clause FROM de l'instruction select.
CREATE VIEW nom_vue
AS
SELECT * FROM nom_vue2;
Bien que cela soit possible, il faut éviter l'accumulation sur plusieurs niveaux afin d'éviter tout problème de gestion lors des suppressions de vue notamment.
La modification d'une vue s'effectue au moyen de la commande ALTER. L'instruction OR REPLACE vu précédemment spécifique à Oracle peut être également utilisée pour modifier la vue.
ALTER VIEW [ nom_base . ] [ propriétaire . ] nom_vue
[ ( nom_colonne [ ,...n ] ) ]
[ WITH { ENCRYPTION | SCHEMABINDING | VIEW_METADATA } [ ,...n ] ]
AS instruction_selection... [ WITH CHECK OPTION ] |
Les vues peuvent être supprimées par l'intermédiaire de la commande DROP.
DROP VIEW nom_vue;
Il est possible de renommer une vue par l'intermédiaire de la commande RENAME.
RENAME nom_vue TO nouveau_nom;
D'autre part, la clause ORDER BY ne peut pas être employée dans l'instruction CREATE VIEW. Cependant, la clause de regroupement GROUP BY peut être utilisée à des fins d'ordonnancement.
Les vues ne possédant pas d'existence physique, peuvent être néanmoins sauvegardées dans une table par l'intermédiaire d'une commande CREATE TABLE.
CREATE TABLE tbl_sauvegarde AS
SELECT col1, ..., colN
FROM nom_vue
[WHERE Condition];
La clause ORDER BY ne peut être utilisée dans la commande SELECT dans le cadre d'une création de vue. Toutefois, la clause de regroupement GROUP BY est utilisable dans ce cas de figure est produit un résultat sensiblement équivalent.
Exemples
CREATE VIEW vue_personnel AS
SELECT * FROM tbl_personnel
CREATE VIEW vue_personnel AS
SELECT sexe, nom, prenom, adresse, cp, ville
FROM tbl_personnel
WHERE service = 'commercial'
CREATE VIEW vue_pers_serv AS
SELECT v.sexe, v.nom, v.prenom, t.poste, t.service
FROM vue_personnel v, tbl_service t
WHERE code_service = 'SC02354L'
GROUP BY v.nom || ', ' || v.prenom;
-- Utilisation d'une vue
SELECT * FROM vue_pers_serv;
UPDATE vue_pers_serv
SET sexe = 'masculin'
WHERE nom = 'Frédérique' AND prenom = 'Jean'
SELECT v1.nom, v2.prenom, v3.service
FROM vue_personnel AS v1, vue_services AS v2
WHERE v1.id_service = v2.id_service
CREATE TABLE tbl_employes AS
SELECT v1.id_service, v2.service, v1.nom, v1.prenom, v1.adresse
FROM vue_personnel AS v1, vue_services AS v2
WHERE v1.id_service = v2.id_service |
Les requêtes de sélection correspondent à des interrogations sur une base de données afin d'en extraire des informations.
Le langage DQL (Data Query Language) propose à cet effet une commande essentielle dans SQL, l'instruction SELECT.
L'instruction SELECT est associée à diverses clauses obligatoires ou optionnelles en vue d'affiner la sélection de données.
Les clauses principales de l'instruction SELECT permettent de désigner une table (FROM), d'appliquer des critères de sélection (WHERE), de regrouper des informations (GROUP BY) selon d'éventuelles conditions (HAVING), d'ordonner ces mêmes informations (ORDER BY) dans un ordre descendant (DESC) ou ascendant (ASC) ou encore de joindre plusieurs tables (JOIN).
Les commandes select et FROM sont utilsées pour sélectionner des tables dans une base de données.
SELECT * | { [ALL | DISTINCT] nom_colonne,...,nom_colonneN }
FROM nom_table
WHERE Condition
Pour sélectionner tous les champs d'une table, il suffit d'utiliser une étoile (*) à la place des noms de champs.
Il est possible de sélectionner de un à plusieurs champs en séparant les noms de champs (ou de colonnes) par une virgule.
Les clauses ALL par défaut et DISTINCT permettent respectivement de sélectionner tous les enregistrements d'une colonne et de ne prendre en compte que chaque enregistrement distinct, soit sans doublons.
La clause FROM cible une ou plusieurs tables à partir desquelles l'extraction des données doit être opérée.
SELECT nom_table.nom_colonne,..., nom_tableN.nom_colonneN
FROM nom_table,..., nom_tableN
La clause WHERE pose une condition dans la sélection des informations. PLusieurs conditions peuvent être enchaînées par un opérateur conjonctif dans cette clause.
SELECT * FROM employe WHERE nom = 'DUPONT'
Les requêtes de sélection peuvent également être utilisées comme sous-requêtes dans une clause conditionnelle WHERE.
SELECT tab1.nom_champ,..., tab1.nom_champN
FROM nom_table AS tab1
WHERE tab1.nom_champ = (SELECT tab2.nom_champ
FROM nom_table AS tab2
WHERE tab2.nom_champ = valeur)
Les sous-requêtes permettent de sélectionner un premier jeu d'enregistrements dans une table tierce qui servira de condition de sélection dans la requête principale.
Exemple
| Librairie |
| ISBN |
Livre |
Editeur |
Prix |
| 1565926978 |
ORACLE SQL : THE ESSENTIAL REFERENCE (EN ANGLAIS) |
O'REILLY |
330.00 |
| 1565929489 |
ORACLE SQL* LOADER : THE DEFINITIVE GUIDE (EN ANGLAIS) |
O'REILLY |
286.00 |
| 2212092857 |
INITIATION A SQL - COURS ET EXERCICES CORRIGES |
EYROLLES |
183.00 |
| 2744009296 |
SQL |
CAMPUSPRESS FRANCE |
62.00 |
| 2744090034 |
MAITRISEZ SQL |
WROX PRESS |
286.00 |
| 2840725029 |
SQL |
ENI |
140.00 |
| 2840828987 |
KIT DE FORMATION MICROSOFT SQL SERVER 2000 ADMINISTRATION SYSTEME |
MICROSOFT PRESS |
284.00 |
SELECT Livre FROM Librairie
' retourne
ORACLE SQL : THE ESSENTIAL REFERENCE (EN ANGLAIS)
ORACLE SQL* LOADER : THE DEFINITIVE GUIDE (EN ANGLAIS)
INITIATION A SQL - COURS ET EXERCICES CORRIGES
SQL
MAITRISEZ SQL
SQL
KIT DE FORMATION MICROSOFT SQL
SERVER 2000 ADMINISTRATION SYSTEME
Les clauses DISTINCT et ALL fournissent une manière de gérer les doublons sur des ensembles de champs obtenus à partir d'une commande SELECT.
La clause DISTINCT sélectionne chaque ligne distincte du résultat de la requête en éliminant les doublons, soit des lignes dont toutes les valeurs de champs sont parfaitement égales.
La commande ALL indique que les doublons peuvent apparaître dans le résultat d'une requête, elle constitue la clause par défaut de la commande SELECT.
SELECT DISTINCT | ALL nom_champ FROM nom_table
Exemple
SELECT DISTINCT Livre FROM Librairie
' retourne
ORACLE SQL : THE ESSENTIAL REFERENCE (EN ANGLAIS)
ORACLE SQL* LOADER : THE DEFINITIVE GUIDE (EN ANGLAIS)
INITIATION A SQL - COURS ET EXERCICES CORRIGES
SQL
MAITRISEZ SQL
KIT DE FORMATION MICROSOFT SQL
SERVER 2000 ADMINISTRATION SYSTEME
SELECT ALL Livre FROM Librairie
' retourne
ORACLE SQL : THE ESSENTIAL REFERENCE (EN ANGLAIS)
ORACLE SQL* LOADER : THE DEFINITIVE GUIDE (EN ANGLAIS)
INITIATION A SQL - COURS ET EXERCICES CORRIGES
SQL
SQL
MAITRISEZ SQL
KIT DE FORMATION MICROSOFT SQL
SERVER 2000 ADMINISTRATION SYSTEME
SELECT nom, adresse FROM personnes
' retourne
DUPONT 1a rue des Cocotiers
JEAN-BON 25 avenue du Général Leclerc
DELAY 48 boulevard des Hêtres
DUPONT 1a rue des Cocotiers
SELECT DISTINCT nom, adresse FROM personnes
' retourne
DUPONT 1a rue des Cocotiers
JEAN-BON 25 avenue du Général Leclerc
DELAY 48 boulevard des Hêtres
Les alias concourrent à améliorer la lisibilité et la concision d'une requête.
Il existe deux types d'alias : les alias de tables et les alias de champs. Ils peuvent également s'appliquer à une fonction d'agrégation retournant des données sous forme de colonnes.
SELECT Alias_table.nom_champ AS Alias_champ
FROM nom_table AS Alias_table
La clause AS affectant un alias à une table ou une colonne, peut être remplacer par un simple espace blanc.
SELECT Alias_table.nom_champ Alias_champ
FROM nom_table Alias_table
Les alias de champs peuvent être des chaînes de caractères composées de mots et d'espaces. Dans ce cas, il faut placer l'alias entre simple guillemet.
SELECT Alias_table.nom_champ AS 'Un alias de champ'
FROM nom_table AS Alias_table
Lors de l'affichage des lignes résultantes, les alias de champs se substitueront aux noms de colonnes. De cette manière, il devient possible d'attribuer des noms de colonnes plus explicites pour les utilisateurs de la base de données.
Les alias sont particulièrement utiles dans le cadre des jointures et des requêtes imbriquées. Dans les deux cas, il devient possible de faire appel à des champs de noms identiques en les distinguant par des préfixes qui sont les alias de table.
-- Jointure
SELECT p.nom, p.prenom, c.num_client,
FROM personne AS p, client AS c
WHERE p.nom = c.nom AND p.prenom = c.prenom
-- Jointure réflexive
SELECT p1.*, p2.* FROM personne AS p1, personne AS p2
WHERE p1.code_postal = p2.code_postal
-- Requête imbriquée
SELECT e.nom, e.salaire FROM employes AS e, service AS s
WHERE (e.id_service, e.salaire) IN
(SELECT id_service, salaire_min FROM Echelle_Salaire
WHERE id_type_emploi = e.id_type_emploi)
AND e.id_service = s.id_service
AND s.code_postal = 77400;
Le langage SQL prévoit également les synonymes de tables, de vues ou de tout autre objet. Les synonymes permettent de dissimuler un nom de table par un autre afin d'éviter qu'un utilisateur accède nommément à un objet qui ne lui appartient guère.
CREATE [ PUBLIC | PRIVATE ] SYNONYM nom_synonyme FOR objet;
CREATE SYNONYM syn_empl FOR tbl_personnel;
Les synonymes peuvent être publics (PUBLIC) donc accessibles dans toute la base de données, et partant, par l'ensemble de ses utilisateurs ou privés (par défaut) donc destinés au seul usage de son créateur et des éventuels bénéficiaires de privilèges d'accès.
Les synonymes peuvent être suprimées par l'intermédaire d'une commande de suppression DROP.
DROP [ PUBLIC | PRIVATE ] SYNONYM nom_synonyme;
DROP SYNONYM syn_empl;
Exemple
SELECT L.Editeur 'Nom des éditeurs',
SUM(L.Prix) 'Total des prix'
FROM Librairie AS L
GROUP BY L.Editeur
HAVING SUM(L.Prix) > 200
' retourne |
| Nom des éditeurs |
Total des prix |
| O'REILLY |
616.00 |
| WROX PRESS |
286.00 |
| MICROSOFT PRESS |
284.00 |
La commande WHERE pose une condition dans la requête de sélection.
SELECT nom_champ
FROM nom_table
WHERE condition
L'expression conditionnelle peut être construite à l'aide de plusieurs prédicats constitués d'opérateurs de comparaisons (= | <> | != | > | > = | !> | < | <= | !<) et séparées par des opérateurs booléens AND, OR ou NOT.
SELECT nom_champ
FROM nom_table
WHERE champ >= valeur AND
( champ2 = valeur2 OR champ3 != valeur3)
La condition consiste à qualifier des enregistrements en fonction de son résultat booléen.
- Si la valeur est True, l'information est sélectionnée.
- Si la valeur est False, l'information n'est pas prise en compte.
La clause WHERE peut accueillir une sous-requête de sélection limitant ainsi les enregistrements sélectionnables dans la requête principale.
Exemple
SELECT Livre FROM Librairie WHERE Prix < 200
' retourne
INITIATION A SQL - COURS ET EXERCICES CORRIGES
SQL
SQL |
La commande GROUP BY spécifie des groupes dans lesquels les lignes de sortie doivent être placées et calcule une valeur de résumé pour chacun des groupes si des fonctions d'agrégation sont employées avec la commande select.
| avg() | retourne la moyenne d'une colonne complète ou d'un regroupement, |
|---|
| count() | retourne le nombre de lignes ou de chaque regroupement, |
|---|
| max() | retourne la valeur maximum d'une colonne ou de chaque regroupement, |
|---|
| min() | retourne la valeur minimum d'une colonne ou de chaque regroupement, |
|---|
| sum() | retourne la somme des valeurs d'une colonne ou de chaque regroupement, |
|---|
Les groupes peuvent se composer de noms de colonne, de résultats ou de colonnes calculées.
SELECT champ, [..., champN, ]Fonction_Agregation(ChampFA)
FROM nom_table
[WHERE Condition]
GROUP BY champ[, ..., champN]
[HAVING Condition_regroupement]
[ORDER BY champX, ...]
SELECT p.professeur, c.classe, avg(c.note)
FROM classe as c, professeurs as p
WHERE c.id_cours = p.id_cours
GROUP BY c.classe, p.professeur
HAVING c.classe = 'Cinquième'
ORDER BY 3, p.professeur;
Une requête de sélection utilisant la clause GROUP BY doit impérativement contenir au moins une fonction d'agrégation. Dans le cas contraire, cette requête ne pourrait être exécutée sans l'émission d'un message d'erreur.
SELECT c.classe, count(c.id_eleve), avg(c.note)
FROM classe as c
GROUP BY classe
ORDER BY 3;
La clause HAVING, généralement employée avec la clause GROUP BY, permet de poser une condition supplémentaire dans la requête de sélection, s'appliquant sur le regroupement.
Tous les champs de la commande SELECT doivent être présents dans la clause HAVING, en commençant par le champ sur lequel doit s'appliquer en priorité le regroupement.
Exemple
SELECT Editeur, SUM(Prix)
FROM Librairie
GROUP BY Editeur
' retourne
| O'REILLY |
616.00 |
| EYROLLES |
183.00 |
| CAMPUSPRESS FRANCE |
62.00 |
| WROX PRESS |
286.00 |
| ENI |
140.00 |
| MICROSOFT PRESS |
284.00 |
|
La clause HAVING spécifie un critère de recherche pour un groupe ou une fonction d'agrégation. HAVING est généralement utilisé avec GROUP BY, sinon HAVING se comporte à l'instar de WHERE.
SELECT nom_champ,
Fonction_Agregation
FROM nom_table
GROUP BY nom_champ2
HAVING "Condition"
La clause HAVING peut contenir un test sur une valeur calculée à l'aide d'une fonction d'agrégation.
SELECT genre, count(*) AS 'Nombre films'
FROM films
GROUP BY genre
HAVING count(*) > 0
Les alias ne peuvent être utilisés au sein d'une clause HAVING, contraignant ainsi à utiliser le nom de colonne ou la fonction d'agrégation sur laquelle la condition doit s'appliquer.
Exemple
SELECT Editeur,
SUM(Prix)
FROM Librairie
GROUP BY Editeur
HAVING SUM(Prix) > 200
' retourne
| O'REILLY |
616.00 |
| WROX PRESS |
286.00 |
| MICROSOFT PRESS |
284.00 |
|
La commande ORDER BY permet de classer alphabétiquement les données retournées par la requête de sélection.
SELECT nom_champ, nom_champ2,..., nom_champN
FROM nom_table
ORDER BY
{nom_champ | 1} [ ASC | DESC
[, ..., {nom_champN | N} ASC | DESC } ]
Le critère de la clause ORDER BY peut être soit le nom, soit le numéro d'une des colonnes sélectionnées par la requête. Les alias de champs ne sont pas acceptés dans cette clause.
-- Tri par ville, nom et prenom
SELECT nom, prenom, adresse, code_postal, ville
FROM clients
ORDER BY 5, 1, 2
La clause ASC par défaut ou DESC provoque respectivement un tri dans un ordre ascendant (0 ... 9 et A ... Z) ou descendant (Z ... A et 9 ... 0).
La clause ASC est implicitement appelée en cas d'omission de l'une d'elles, provoquant donc un tri en ordre ascendant par défaut.
Exemple
SELECT Editeur,
SUM(Prix)
FROM Librairie
ORDER BY Editeur
-- est équivalent à
SELECT Editeur,
SUM(Prix)
FROM Librairie
ORDER BY 1 ASC
' retourne
| CAMPUSPRESS FRANCE |
62.00 |
| ENI |
140.00 |
| EYROLLES |
183.00 |
| MICROSOFT PRESS |
284.00 |
| O'REILLY |
616.00 |
| WROX PRESS |
286.00 |
|
les requêtes de sélection demeurent les plus intéressantes, lorsqu'elles s'appliquent à plusieurs tables. Mais pour cela, il est nécessaire d'exécuter des commandes de jointure afin de pouvoir extraire des données de ces tables.
Il existe de nombreuses manières de joindre des tables dépendant souvent de l'implémentation utilisée. Néanmoins, la plupart des commandes de jointures accomplissent leurs opérations sur des colonnes communes aux différentes tables. Ainsi, les jointures sont possible uniquement sur des tables possédant des colonnes correspondantes comme une clé étrangère se relierait à une clé primaire.
Des tables mises en relation les unes avec les autres, peuvent facilement délivrer des informations recoupées. Si aucune instruction de jointure n'est fournie dans une requête de sélection, alors cette dernière renverra la totalité des lignes présentes dans les tables concernées.
Une jointure d'égalité symbolisée par EQUIJOIN ou INNER JOIN crée une relation de correspondance entre des tables.
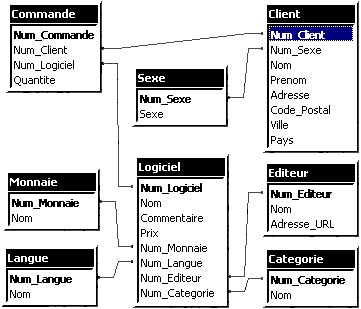
SELECT l.Nom, e.Nom, c.Nom
FROM Logiciel AS l, Editeur AS e, Categorie AS c
WHERE l.Num_Editeur = e.Num_Editeur,
AND l.Num_Categorie = c.Num_Categorie
SELECT l.Nom, c.Quantite, cl.Nom, c.Prenom
FROM Logiciel AS l
INNER JOIN Commande AS c INNER JOIN Client AS cl
ON c.Num_Client = cl.Num_Client
ON l.Num_Logiciel = c.Num_Logiciel
SELECT cl.Nom, cl.Prenom, l.Nom,
(l.Prix * cmd.Quantite) AS Montant, m.Nom
FROM Logiciel l, Client cl, Commande cmd, Monnaie m
WHERE cmd.Num_Client = cl.Num_Client
AND l.Num_Logiciel = cmd.Num_Logiciel
AND l.Num_Monnaie = m.Num_Monnaie
Une jointure de non-égalité NON-EQUIJOIN permet de sélectionner des enregistrements dont les valeurs de colonnes ne correspondent pas.
SELECT s.Sexe, cl.Nom, cl.Prenom
FROM Logiciel AS l, Commande AS cmd, Sexe AS s
WHERE cl.Num_Client != cmd.Num_Client,
AND cl.Num_Sexe = s.Num_Sexe
Les jointures externes OUTER JOIN sont employées pour retourner tous les enregistrements, y compris ceux ne possédant aucune correspondance. Ces jointures peuvent s'appliquer à gauche (LEFT), à droite (RIGHT) ou sur les deux (FULL).
SELECT cl.Nom, cl.Prenom, cmd.Num_Commande
FROM Client AS cl, Commande AS c
WHERE cl.Num_Client (+) = cmd.Num_Commande
SELECT cl.Nom, cl.Prenom, cmd.Num_Commande
FROM Client AS cl
LEFT OUTER JOIN Commande AS c
ON cl.Num_Client = cmd.Num_Commande
-- est équivalent à
SELECT cl.Nom, cl.Prenom, cmd.Num_Commande
FROM Commande AS c
RIGHT OUTER JOIN Client AS cl
ON cl.Num_Client = cmd.Num_Commande
Les jointures réflexives sont utilisées pour joindre une table à elle-même.
SELECT cl1.Nom, cl1.Prenom, cl2.Nom, cl2.Prenom
FROM Client AS cl1, Client AS cl2
WHERE cl1.Num_Client = cl2.Num_Client
SELECT cl1.Nom, cl1.Prenom, cl2.Nom, cl2.Prenom
FROM Client AS cl1
SELF JOIN Client AS cl2
ON cl1.Num_Client = cl2.Num_Client
Les commandes de jointures de tables donnent la possibilité d'appliquer des requêtes sur plusieurs tables d'une base de données.
SELECT tab.nom_champ
FROM nom_table As tab
[INNER | {{LEFT | RIGHT | FULL } [ OUTER]}]
JOIN nom_table2 As tab2
ON Condition
La condition de la commande ON permet de comparer les tables jointes par l'intermédiaire de champs dont les valeurs sont identiques et comparables.
INNER JOIN (option par défaut) indique toutes les paires correspondantes des lignes renvoyées et supprime les lignes n'ayant pas de correspondance entre les deux tables.
FULL OUTER JOIN indique qu'une ligne de la table de gauche ou de droite, ne respectant pas la condition de jointure, est comprise dans le jeu de résultats et que les colonnes de sortie correspondant à l'autre table comportent des valeurs NULL.
LEFT OUTER JOIN indique que toutes les lignes de la table de gauche ne respectant pas la condition de jointure sont incluses dans le jeu de résultats, et que les colonnes de sortie de l'autre table ont des valeurs NULL en plus de toutes les lignes renvoyées par la jointure interne.
RIGHT OUTER JOIN indique que toutes les lignes de la table de droite ne respectant pas la condition de jointure sont comprises dans le jeu de résultats, et que les colonnes de sortie correspondant à l'autre table ont des valeurs NULL en plus de toutes les lignes renvoyées par la jointure interne.
Exemple
| Edition |
| Editeur |
Adresse URL |
| O'REILLY |
http://www.oreilly.com/ |
| CAMPUSPRESS FRANCE |
http://www.campuspress.fr/ |
| WROX PRESS |
http://www.wrox.com/ |
| MICROSOFT PRESS |
http://www.microsoft.com/mspress/ |
SELECT L.ISBN, L.Editeur, E.Adresse
FROM Librairie As L
INNER JOIN Edition As E
ON L.Editeur = E.Editeur
| ' retourne |
| ISBN |
Editeur |
Adresse |
| 1565926978 |
O'REILLY |
http://www.oreilly.com/ |
| 1565929489 |
O'REILLY |
http://www.oreilly.com/ |
| 2744009296 |
CAMPUSPRESS
FRANCE |
http://www.campuspress.fr/ |
| 2744090034 |
WROX PRESS |
http://www.wrox.com/ |
| 2840828987 |
MICROSOFT
PRESS |
http://www.microsoft.com/mspress/ |
SELECT L.ISBN, L.Editeur, E.Adresse
FROM Librairie As L
LEFT OUTER JOIN Edition As E
ON L.Editeur = E.Editeur
| ' retourne |
| ISBN |
Editeur |
Adresse |
| 1565926978 |
O'REILLY |
http://www.oreilly.com/ |
| 1565929489 |
O'REILLY |
http://www.oreilly.com/ |
| 2212092857 |
EYROLLES |
NULL |
| 2744009296 |
CAMPUSPRESS
FRANCE |
http://www.campuspress.fr/ |
| 2744090034 |
WROX PRESS |
http://www.wrox.com/ |
| 2840725029 |
ENI |
NULL |
| 2840828987 |
MICROSOFT
PRESS |
http://www.microsoft.com/mspress/ |
Les commandes DML (Data Manipulate Language) permettent de manipuler les informations d'une base de données.
Il existe trois commandes destinées à mettre à jour (UPDATE), insérer (INSERT) ou supprimer (DELETE) des données.
Ce genre de manipulation sur une base de données nécessite également l'emploi de commandes transactionnelles, afin de valider ou invalider les modifications résultantes.
L'exécution d'une commande DML constitue une transaction qui doit être initiée par SET TRANSACTION et terminée par COMMIT pour la validation ou ROLLBACK pour l'annulation.
SET TRANSACTION
' Instructions_DML
COMMIT | ROLLBACK
Une à plusieurs instructions DML constituent une séquence et peuvent être associées au sein de cette structure transactionnelle.
Dans ce cas, il est possible de placer des points de sauvegarde entre les commandes DML par l'intermédiaire de SAVEPOINT dans le but de créer des niveaux d'annulation.
SET TRANSACTION
' Instructions_DML
SAVEPOINT nom_point1
' Instructions_DML
SAVEPOINT nom_point2
' Instructions_DML
COMMIT | { ROLLBACK TO nom_point1 | nom_point2 }
Avec une telle structure, un programme automatisé ou un utilisateur détient la capacité d'enregistrer toutes les modifications ou de les annuler jusqu'à un certain point de sauvegarde.
La commande INSERT INTO permet d'ajouter des données dans une table.
INSERT INTO Nom_Table
(Champ_1, Champ_2, ..., Champ_N)
VALUES (Valeur_1, Valeur_2, ..., Valeur_N)
L'ajout de données dans une table demande évidemment, la parfaite connaissance de la structure de la table, puisqu'il est nécessaire de fournir le nom des champs dans le bon ordre et des informations correspondant à leur type de données respectifs.
Les valeurs de colonnes doivent être encadrées par des guillemets simples (') s'il s'agît de chaîne de caractères, les nombres ne nécessitant pas de guillemets.
VALUES ('Chaîne de caractères', 100)
Il est possible de ne pas énumérer les noms de colonnes si l'ajout de données concerne un enregistrement complet de la table.
INSERT INTO Nom_Table
VALUES (Valeur_1, Valeur_2, ..., Valeur_N)
En général, la citation des noms de colonnes est pertinente pour un ajout de données limité à certain champs de la table.
INSERT INTO Nom_Table
(Champ_1, Champ_2)
VALUES (Valeur_1, Valeur_2)
Il est également possible d'insérer des données provenant d'une autre table par l'intermédiaire d'une commande select. Une clause WHERE peut être ajoutée avec des conditions pouvant comporter des sous-requêtes.
INSERT INTO Nom_Table
(champ, ..., champN)
SELECT nom_champ, ..., Nom_champN
FROM nom_table
WHERE Condition
Dans ce cas, chacun des champs de la table cible et de ceux de la table source doivent être évidemment de même type et de même domaine de valeurs afin d'éviter la génération d'erreurs systèmes et de conserver la cohérence de la table cible.
L'insertion de valeur nulle peut se faire par l'intermédiaire du mot-clé NULL ou d'une chaîne vide.
INSERT INTO Nom_Table
(Champ_1, Champ_2)
VALUES (Valeur_1, NULL)
INSERT INTO Nom_Table
(Champ_1, Champ_2)
VALUES (Valeur_1, '')
Exemple
INSERT INTO Fiche_Personne
(ID, Nom, Prenom, CP)
VALUES (75036, ANATOLIS, Ivan, 92100)
Crée une ligne de données dans la table |
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| 187 |
JANVIER |
Denis |
77870 |
| 1097 |
NAPOLI |
Victor |
75020 |
| 10852 |
ARCHI |
Bertrand |
93330 |
| 20140 |
MULLER |
Arthur |
75020 |
| 1654327 |
NAPOLI |
Julien |
75020 |
| 7503609 |
ANATOLIS |
Ivan |
92100 |
La commande UPDATE permet de mettre à jour des données existantes au sein d'une table.
UPDATE Nom_Table
SET Col_1 = Nouv_Val_1[, Col_2 = Nouv_Val_2[, ..., Col_N = Nouv_Val_N]]
[WHERE Condition]
UPDATE personnes
SET nom = 'DUPONT', adresse = '12b rue du Commerce'
WHERE nom = 'DUPOND' AND prenom = 'Albert'
|
La commande UPDATE peut mettre à jour les données de manières différentes :
- La valeur d'une seule colonne en ne citant qu'une colonne associéé à sa nouvelle valeur.
- Plusieurs colonnes simultanément en citant plusieurs colonnes avec leur valeur respective.
- Par l'intermédiaire d'une clause conditionnelle affectant quelques lignes de données, les valeurs de plusieurs enregistrements en même temps.
Une opération de mise à jour peut être effectuée sur un jeu d'enregistrements en utilisant une sous-requête de sélection.
UPDATE nom_table1 AS tab1
SET tab1.nom_champ = valeur
WHERE tab1.nom_champ opérateur (SELECT tab2.nom_champ
FROM nom_table2 AS tab2
WHERE Condition)
UPDATE produits AS p
SET p.prix = p.prix + (p.prix * 5 / 100)
WHERE p.marque IN (SELECT fournisseur
FROM fournisseurs
WHERE decision = 'hausse')
Exemple
UPDATE Fiche_Personne
SET CP = 75012
WHERE Nom = "JANVIER" AND Prenom = "Denis"
Met à jour la valeur CP sur une seule colonne |
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| 187 |
JANVIER |
Denis |
75012 |
| 1097 |
NAPOLI |
Victor |
75020 |
| 10852 |
ARCHI |
Bertrand |
93330 |
| 20140 |
MULLER |
Arthur |
75020 |
| 1654327 |
NAPOLI |
Julien |
75020 |
| 7503609 |
ANATOLIS |
Ivan |
92100 |
UPDATE Fiche_Personne
SET CP = 95200
WHERE Nom = "NAPOLI"
Met à jour la valeur CP sur deux enregistrements |
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| 187 |
JANVIER |
Denis |
75012 |
| 1097 |
NAPOLI |
Victor |
95200 |
| 10852 |
ARCHI |
Bertrand |
93330 |
| 20140 |
MULLER |
Arthur |
75020 |
| 1654327 |
NAPOLI |
Julien |
95200 |
| 7503609 |
ANATOLIS |
Ivan |
92100 |
La commande DELETE FROM permet de supprimer des enregistrements au sein d'une table.
DELETE FROM Nom_Table
[WHERE Condition]
DELETE FROM personnes
WHERE ville = Saint-Ignace-du-Lac' AND pays = 'Québec';
La clause conditionnelle WHERE détermine les enregistrements à sélectionner pour effectuer leur suppression complète de la table.
Une sous-requête peut être utilisée pour sélectionner des enregistrements à supprimer.
DELETE FROM Nom_Table AS tab1
WHERE tab1.nom_champ opérateur (SELECT tab2.nom_champ
FROM nom_table AS tab2
WHERE Condition)
DELETE FROM personnes
WHERE ville IN (SELECT ville FROM Projet_Barrage)
Si aucune condition n'est spécifiée, alors tous les enregistrements de la table seraient purement et simplement supprimés.
DELETE FROM personne
Exemple
DELETE FROM Fiche_Personnel
WHERE Nom = "NAPOLI"
Supprime deux enregistrements repérés par : Nom = "NAPOLI" |
| Fiche_Personne |
| id |
Nom |
Prenom |
CP |
| 187 |
JANVIER |
Denis |
75012 |
| 1097 |
NAPOLI |
Victor |
95200 |
| 10852 |
ARCHI |
Bertrand |
93330 |
| 20140 |
MULLER |
Arthur |
75020 |
| 1654327 |
NAPOLI |
Julien |
95200 |
| 7503609 |
ANATOLIS |
Ivan |
92100 |
Les commandes DCL (Data Control Language) permettent la gestion des droits d'accès aux objets d'une base de données.
Un utilisateur de base de données doit posséder un compte de sécurité afin d'accéder aux tables ou à tout autre élément.
Pour cela, il faut non seulement que l'utilisateur soit créé mais également que des privilèges lui soient accordés.
Des permissions peuvent être attribuées explicitement à un utilisateur ou implicitement si ce dernier appartient à un rôle.
Un rôle est un objet SQL spécifique auquel est attribué un ou plusieurs privilèges. Un rôle peut être affecté à des utilisateurs qui posséderont alors les autorisations qui lui sont accordées.
En outre, les commandes DCL servent à modifier ou à supprimer des privilèges, voire même des utilisateurs ou des rôles.
La commande CREATE USER permet la création d'un utilisateur dans la base de données.
Syntaxe sous Oracle
CREATE USER nom_utilisateur
IDENTIFIED
{ BY mot_passe | EXTERNALLY | GLOBALLY AS 'nom_externe' }
[
{
DEFAULT TABLESPACE espace_table
| TEMPORARY TABLESPACE espace_table
| QUOTA { entier [ K | M ] | UNLIMITED } ON espace_table
[QUOTA { entier [ K | M ] | UNLIMITED } ON espace_tableN]
| PROFILE profile
| PASSWORD EXPIRE
| ACCOUNT { LOCK | UNLOCK }
}
]
[ N_fois... ]; |
La clause IDENTIFIED indique de quelle manière Oracle authentifie un utilisateur.
La clause BY mot_passe indique par quel mot de passe un utilisateur est autorisé à se connecter à la base de données.
La clause USING package permet de créer un rôle d'application, lequel est un rôle qui peut être activé seulemet par les applications en utilisant un package autorisé.
La clause EXTERNALLY indique la création d'un utilisateur externe qui doit être authentifié par un service externe avant l'activation du rôle.
La clause GLOBALLY indique la création d'un utilisateur global qui doit être autorisé à utiliser le rôle par le service de répertoire d'entreprise avant que le rôle ne soit activé.
Un rôle sous Oracle s'active en utilisant l'instruction SET ROLE.
La clause DEFAULT TABLESPACE spécifie l'espace de table par défaut pour les objets créés par l'utilisateur. Si la clause est omise, les objets vont dans un espace de table SYSTEM.
La clause TEMPORARY TABLESPACE spécifie l'espace de table pour les ségments temporaires d'utilisateur. Si la clause est omise, l'espace de table SYSTEM accueille les ségments.
La clause QUOTA permet à l'utilisateur d'allouer jusqu'à un certain espace en nombre d'octets dans l'espace de table. K signifie kilo-octets, M, méga-octets.
L'option UNLIMITED fournit à l'utilisateur un espace illimité.
La clause profile indique le profile à affecter à l'utilisateur.
La clause PASSWORD EXPIRE indique si le mot de passe de l'utilisateur doit expirer.
La clause ACCOUNT vérouille ou dévérouille le compte d'utilisateur.
Le processus de création d'un utilisateur dans une base de données SQL Server différe fortement puisqu'il est nécessaire de faire appel à une procédure stockée.
EXEC sp_adduser [ @loginame = ] 'login'
[, [ @name_in_db = ] 'nom_utilisateur' ]
[, [ @grpname = ] 'groupe' ]
La suppression d'un utilisateur s'effectue par l'intermédiaire d'une autre procédure stockée.
sp_dropuser [ @name_in_db = ] 'nom_utilisateur'
Exemple
CREATE USER "webmaster@site.com" IDENTIFIED EXTERNALLY;
CREATE USER utilisateur_invite
IDENTIFIED BY site_produit
DEFAULT TABLESPACE espace_invite
QUOTA 5M ON demonstration
TEMPORARY TABLESPACE temp_demo
QUOTA 1M ON system
PROFILE util_inv
PASSWORD EXPIRE;
EXEC sp_adduser 'jj_annaud', 'raphael', 'invite' |
La commande ALTER USER permet de modifier les paramètres de connexion à une base de données pour un utilisateur.
La modification d'un utilisateur porte sur plusieurs aspects de son compte, tels que :
- l'espace de table alloué pour les objets utilisateurs,
- l'affectation de rôles reflétant les privilèges d'accès,
- le mode d'authentification permettant la connexion à la base de données,
- l'assignation d'un profile, etc..
Syntaxe sous Oracle
ALTER USER
{ user
{ IDENTIFIED
{ BY mot_passe [ REPLACE ancien_motpasse ]
| EXTERNALLY
| GLOBALLY AS 'nom_externe'
}
| DEFAULT TABLESPACE espace_table
| TEMPORARY TABLESPACE espace_table
| QUOTA { integer [ K | M ]
| UNLIMITED
} ON espace_table
[ QUOTA { integer [ K | M ]
| UNLIMITED
} ON espace_table
]...
| PROFILE profile
| DEFAULT ROLE { role [, role ]...
| ALL [ EXCEPT role [, role ]... ]
| NONE
}
| PASSWORD EXPIRE
| ACCOUNT { LOCK | UNLOCK }
}
[ { IDENTIFIED
{ BY mot_passe [ REPLACE ancien_motpasse ]
| EXTERNALLY
| GLOBALLY AS 'external_name'
}
| DEFAULT TABLESPACE espace_table
| TEMPORARY TABLESPACE espace_table
| QUOTA { integer [ K | M ]
| UNLIMITED
} ON espace_table
[ QUOTA { integer [ K | M ]
| UNLIMITED
} ON espace_table
]...
| PROFILE profile
| DEFAULT ROLE { role [, role ]...
| ALL [ EXCEPT role [, role ]... ]
| NONE
}
| PASSWORD EXPIRE
| ACCOUNT { LOCK | UNLOCK }
}
]...
| utilisateur [, utilisateur ]... proxy_clause; |
La clause IDENTIFIED indique de quelle manière Oracle authentifie un utilisateur.
La clause BY mot_passe indique par quel mot de passe un utilisateur est autorisé à se connecter à la base de données.
La clause USING package permet de créer un rôle d'application, lequel est un rôle qui peut être activé seulemet par les applications en utilisant un package autorisé.
La clause EXTERNALLY indique la création d'un utilisateur externe qui doit être authentifié par un service externe avant l'activation du rôle.
La clause GLOBALLY indique la création d'un utilisateur global qui doit être autorisé à utiliser le rôle par le service de répertoire d'entreprise avant que le rôle ne soit activé.
Un rôle sous Oracle s'active en utilisant l'instruction SET ROLE.
La clause DEFAULT TABLESPACE spécifie l'espace de table par défaut pour les objets créés par l'utilisateur. Si la clause est omise, les objets vont dans un espace de table SYSTEM.
La clause TEMPORARY TABLESPACE spécifie l'espace de table pour les ségments temporaires d'utilisateur. Si la clause est omise, l'espace de table SYSTEM accueille les ségments.
La clause QUOTA permet à l'utilisateur d'allouer jusqu'à un certain espace en nombre d'octets dans l'espace de table. K signifie kilo-octets, M, méga-octets.
L'option UNLIMITED fournit à l'utilisateur un espace illimité.
La clause profile indique le profile à affecter à l'utilisateur.
La clause PASSWORD EXPIRE indique si le mot de passe de l'utilisateur doit expirer.
La clause ACCOUNT vérouille ou dévérouille le compte d'utilisateur.
La clause DEFAULT ROLE spécifie des rôles par défaut à l'utilisateur.
Les clauses GRANT et REVOKE donne respectivement l'autorisation et l'interdiction de la connection.
La clause CONNECT THROUGH identifie le proxy de connexion à Oracle
La clause WITH ROLE autorise le proxy à se connecter comme l'utilisateur spécifié et à activer seulement les rôles spécifiés.
La clause WITH ROLE ALL EXCEPT autorise la proxy à se connecter comme l'utilisateur spécifié et à activer tous les rôles à l'exception de ceux spécifiés.
La clause WITH NO ROLES autorise le proxy à se connecter comme l'utilisateur spécifié, mais interdit le proxy d'activer n'importe lequel des rôles de cet utilisateur après la connexion.
La clause AUTHENTICATED USING permet une authentification par proxy pour être manipulé par une autre source que le proxy. Cette clause est adéquat seulement pour la clause GRANT CONNECT THROUGH.
La clause PASSWORD entraîne la présentation par le proxy du mot de passe de base de données de l'utilisateur pour l'authentification.
La clause DISTINGUISHED name autorise le proxy à agir comme l'utilisateur identifié globalement indiqué par le nom distingué.
La clause CERTIFICATE autorise le proxy à agir comme l'utilisateur identifié globalement dont le nom distingué est contenu dans le certificat possédant un type et une version précisés.
Exemple
ALTER USER jean_francois
IDENTIFIED BY commercial
DEFAULT TABLESPACE ser_com;
ALTER USER poste_compta
PROFILE pr_cpt;
ALTER USER jc_merite
GRANT CONNECT THROUGH cpt_2
WITH ROLE utilisateur_restreint; |
La commande CREATE ROLE permet de créer un rôle auquel sera affecté par la commande GRANT des privilèges.
Par la suite, des utilisateurs peuvent devenir membres d'un rôle et en conséquence hériter de l'ensemble des privilèges accordés à ce rôle.
Syntaxe sous Oracle
CREATE ROLE nom_rôle
[
NOT IDENTIFIED
|
IDENTIFIED
{
BY mot_passe
|
USING [schéma .] package
|
EXTERNALLY
|
GLOBALLY
}
];
La clause NOT IDENTIFIED spécifie que le rôle est autorisé dans la base de données et qu'aucun mot de passe n'est nécessaire.
La clause IDENTIFIED indique qu'un utilisateur doit être autorisé par la méthode spécifiée avant que le rôle ne soit activé par l'instruction SET ROLE.
La clause BY mot_passe indique qu'un utilisateur est autorisé dans la base de données à condition qu'un mot de passe correct soit fourni afin d'activer le rôle.
La clause USING package permet de créer un rôle d'application, lequel est un rôle qui peut être activé seulemet par les applications en utilisant un package autorisé.
La clause EXTERNALLY indique la création d'un utilisateur externe qui doit être autorisé par un service externe avant l'activation du rôle.
La clause GLOBALLY indique la création d'un utilisateur global qui doit être autorisé à utiliser le rôle par le service de répertoire d'entreprise avant que le rôle ne soit activé.
Un rôle sous Oracle s'active en utilisant l'instruction SET ROLE.
SET ROLE
{
nom_rôle [IDENTIFIED BY mot_passe]
[, nom_rôleN [IDENTIFIED BY mot_passe]]
| ALL [EXCEPT nom_rôle [, nom_rôle]]
| NONE
};
La modification d'un rôle est accomplie par ALTER ROLE et la suppression par DROP ROLE.
ALTER ROLE nom_rôle
{
NOT IDENTIFIED
|
{
BY mot_passe
|
USING [schéma .] package
|
EXTERNALLY
|
GLOBALLY
}
};
DROP ROLE nom_rôle;
L'attribution (GRANT) ou la révocation (REVOKE) d'un, plusieurs (ROLE) ou tous les rôles à l'exception de certain (ALL EXCEPT) à un utilisateur peut être faite par l'entremise de la commande ALTER USER.
ALTER USER nom_utilisateur [, nom_utilisateurN ]
{
{ GRANT | REVOKE } CONNECT THROUGH proxy
WITH
{
{
ROLE { nom_rôle [, nom_rôleN]
|
ALL EXCEPT nom_rôle [, nom_rôleN]
}
|
NO ROLES
};
La commande ALTER USER permet de même, d'attribuer un à plusieurs rôles par défaut à un seul utilisateur.
ALTER USER nom_utilisateur
DEFAULT ROLE
{
{ nom_rôle [, nom_rôleN] }
|
{ ALL [EXCEPT nom_rôle [, nom_rôleN]] }
|
NONE
};
Syntaxe sous SQL Server
Le processus de création d'un rôle sous SQL Server différe puisqu'il est nécessaire de passer par une procédure stockée du système.
EXEC sp_addrole [ @rolename = ] 'nom_rôle'
[ , [ @ownername = ] 'propriétaire' ]
L'ajout d'un membre à un rôle, s'effectue par l'intermédiaire d'une autre procédure stockée.
EXEC sp_addrolemember [ @rolename = ] 'nom_rôle' ,
[ @membername = ] 'compte_sécurité'
La suppression d'un membre d'un rôle s'accomplit par sp_droprolemember.
sp_droprolemember [ @rolename = ] 'nom_rôle' ,
[ @membername = ] 'compte_sécurité'
La suppression du rôle s'effectue par sp_droprole.
sp_droprole [ @rolename = ] 'nom_rôle'
Exemple
-- Sous Oracle
CREATE ROLE role_utilisateur;
CREATE ROLE role_developpeur IDENTIFIED GLOBALLY;
-- Sous SQL Server
EXEC sp_addrole 'role_developpeur', 'dbo'
-- Activation des rôles sous Oracle
SET ROLE role_developpeur, role_utilisateur;
-- Utilisation des rôles
GRANT SELECT, UPDATE ON uneTable TO role_utilisateur
GRANT ALL ON uneAutreTable TO role_developpeur
GRANT role_utilisateur TO id_utilisateur, id_utilisateur2
GRANT role_developpeur TO id_developpeur, id_developpeur2 |
La commande GRANT permet d'attribuer un ou plusieurs privilèges à un utilisateur ou un rôle sur des instructions (create database, create table, create view, etc.) ou divers objets tels que des tables, des vues, des colonnes ou encore des procédures stockées.
Syntaxe sous SQL Server
GRANT
{
{
{ ALL | instruction [ ,...n ] }
TO compte_sécurité [ ,...n ]
}
|
{
{ ALL [ PRIVILEGES ] | permission [ ,...n ] }
{
[ ( nom_colonne [ ,...n ] ) ] ON { nom_table | nom_vue }
| ON { nom_table | nom_vue } [ ( nom_colonne [ ,...n ] ) ]
| ON { procédure_stockée | procédure_étendue }
| ON { fonction_utilisateur }
}
TO compte_sécurité [ ,...n ]
[ WITH GRANT OPTION ]
[ AS { groupe | rôle } ]
}
} |
Les clauses TO et FROM indiquent la liste des comptes de sécurité.
La cause ALL indique l'attribution de toutes les autorisations possibles pour le compte de sécurité indiqué.
La clause PRIVILEGES est facultative. En fait elle n'est inclus que pour se conformer aux spécifications SQL-92.
La clause ON indique l'application des autorisations à un objet indiqué.
La commande WITH GRANT OPTION indique la possibilité pour le compte de sécurité de pouvoir lui-même accorder des autorisations à d'autres utilisateurs.
La clause AS {groupe | rôle} indique le nom facultatif d'un groupe ou d'un rôle pour lequel les autorisations seront accordées.
Syntaxe sous Oracle
GRANT
{
{
{ système_privilège | rôle | ALL PRIVILEGES }
[, { système_privilègeN | rôle | ALL PRIVILEGES }]
TO
{
{ utilisateur | rôle | PUBLIC }
[, { utilisateurN | rôle | PUBLIC }]
}
[IDENTIFIED BY mot_passe] [WITH ADMIN OPTION]
}
|
{
{ objet_privilège | ALL [PRIVILEGES] }
[( nom_colonne [, nom_colonne]... )]
[, { objet_privilègeN | ALL [PRIVILEGES] }
[( nom_colonne [, nom_colonneN]... )]]
ON
{
{ schema . objet }
|
{
{ DIRECTORY nom_répertoire }
|
{ JAVA { SOURCE | RESOURCE } [schéma .] objet }
}
}
TO
{
{ utilisateur | rôle | PUBLIC }
[, { utilisateurN | rôle | PUBLIC }]
}
[WITH GRANT OPTION] [WITH HIERARCHY OPTION]
}
}; |
La clause IDENTIFIED BY permet d'identifier un utilisateur existant par un mot de passe ou pour créer un utilisateur inexistant.
La clause WITH ADMIN OPTION fournit à un utilisateur la possibilité d'administrer un rôle.
La cause ALL PRIVILEGES indique l'attribution de toutes les autorisations appliquées au compte de sécurité indiqué.
L'option PUBLIC indique l'attribution de privilèges ou de rôles à tous les utilisateurs.
La clause ON indique l'application des autorisations sur un objet indiqué.
La clause DIRECTORY indique l'objet DIRECTORY sur lequel les privilèges doivent être accordés.
La clause JAVA { SOURCE | RESOURCE } permet de spécifier une source Java ou l'objet de schéma de ressource sur lequel les privilèges doivent être accordés.
La clause FROM indique la liste des comptes de sécurité.
La clause TO indique la liste des comptes de sécurité.
La commande WITH GRANT OPTION indique la possibilité pour le compte de sécurité de pouvoir lui-même accorder des privilèges à d'autres utilisateurs.
La clause WITH HIERARCHY OPTION indique la permission d'étendre les privilèges d'objets spécifiés à tous les sous-objets.
Exemple
-- Permissions sur des instructions
GRANT
CREATE PROCEDURE,
CREATE ANY PROCEDURE,
ALTER ANY PROCEDURE,
DROP ANY PROCEDURE,
EXECUTE ANY PROCEDURE
TO developpeur
WITH ADMIN OPTION;
-- Permissions sur des objets
GRANT INSERT, UPDATE, DELETE
ON tbl_produit
TO 'jk_fort', 'f_troyes'
GRANT
DELETE,
INSERT,
SELECT,
UPDATE,
ALTER
ON tbl_administration TO a_frederic, a_lucie
GRANT ALL ON tbl_administration TO a_jeanpierre, a_luciola
GRANT SELECT ON tbl_livres TO invite |
La commande REVOKE permet de révoquer des privilèges qui ont été attribués à un utilisateur ou à un rôle sur des instructions ou divers objets tels que des tables, des vues, des colonnes ou encore des procédures stockées.
Syntaxe sous SQL Server
REVOKE
{
{
{ ALL | instruction [ ,...n ] }
FROM compte_sécurité [ ,...n ]
}
|
{
[ GRANT OPTION FOR ]
{ ALL [ PRIVILEGES ] | permission [ ,...n ] }
{
[ ( nom_colonne [ ,...n ] ) ] ON { nom_table | nom_vue }
| ON { nom_table | nom_vue } [ ( nom_colonne [ ,...n ] ) ]
| ON { procédure_stockée | procédure_étendue }
| ON { fonction_utilisateur }
}
{ TO | FROM }
compte_sécurité [ ,...n ]
[ CASCADE ]
[ AS { groupe | rôle } ]
}
} |
La commande GRANT OPTION FOR indique la suppression des autorisations WITH GRANT OPTION provoquant la conservation des autorisations à un utilisateur tout en ne pouvant plus en accorder à d'autres.
La cause ALL indique la suppression de toutes les autorisations appliquées au compte de sécurité indiqué.
La clause PRIVILEGES est facultative. En fait elle n'est inclus que pour se conformer aux spécifications SQL-92.
Les clauses TO et FROM indiquent la liste des comptes de sécurité.
La clause CASCADE indique la suppression des autorisations pour le compte de sécurité et de toutes les autres qui auraient été accordées par le propriétaire de ce compte.
La clause AS {groupe | rôle} indique le nom facultatif d'un groupe ou d'un rôle pour lequel les autorisations seront supprimées.
Syntaxe sous Oracle
REVOKE
{
{
{ système_privilège | rôle | ALL PRIVILEGES }
[, { système_privilège | rôle | ALL PRIVILEGES }]
FROM
{
{ utilisateur | rôle | PUBLIC }
[, { utilisateurN | rôle | PUBLIC }]
}
}
|
{
{ objet_privilège | ALL [PRIVILEGES] }
[( nom_colonne [, nom_colonne]... )]
[, { objet_privilègeN | ALL [PRIVILEGES] }
[( nom_colonne [, nom_colonneN]... )]]
ON
{
{ schéma . objet }
|
{
{ DIRECTORY nom_répertoire }
|
{ JAVA { SOURCE | RESOURCE } [schéma .] objet }
}
}
FROM
{
{ utilisateur | rôle | PUBLIC }
[, { utilisateurN | rôle | PUBLIC }]
}
[ CASCADE CONSTRAINTS ] [ FORCE ]
}
}
[, ... ]
; |
La clause ALL PRIVILEGES indique la suppression de toutes les autorisations appliquées au compte de sécurité indiqué.
L'option PUBLIC indique la révocation des privilèges ou des rôles pour tous les utilisateurs.
La clause DIRECTORY indique l'objet DIRECTORY sur lequel les privilèges doivent être révoqués.
La clause JAVA { SOURCE | RESOURCE } permet de spécifier une source Java ou l'objet de schéma de ressource sur lequel les privilèges doivent être révoqués.
La clause FROM indique la liste des comptes de sécurité.
La clause CASCADE CONSTRAINTS annule les contraintes d'intégrité référentielle et est applicable uniquement à une révocation du privilège REFERENCES ou ALL PRIVILEGES.
La clause FORCE permet de révoquer les privilèges EXECUTE sur les objets définis par l'utilisateur avec des tables ou de types de dépendances.
Exemple
REVOKE SELECT ON tbl_employee TO role_employee
REVOKE UPDATE
ON vue_personnel FROM PUBLIC; |
Les commandes transactionnelles permettent de contrôler des transactions se déroulant dans un système de gestion de base de données relationnelle (SGBDR).
Les transactions sont des séquences de tâches s'effectuant dans un ordre logique par l'intermédiaire de l'utilisateur ou d'une automatisation.
Les tâches peuvent être essentiellement des commandes DML; d'insertion (INSERT), de suppression (DELETE) ou de modification (UPDATE) d'objets dans une base de données.
Ces diverses tâches peuvent être annulées en cours d'exécution puisqu'elles possèdent un commencement et une fin.
Au terme de la tâche, il est nécessaire de sauvegarder les changements. Toutefois, aucun enregistrement n'est effectué si la tâche a échoué pour une raison quelconque.
Il existe, donc, quatres commandes transactionnelles principales pour contrôler ces séquences.
Les commandes transactionnelles
| Commande |
| Description |
| { SET | BEGIN } TRANSACTION; |
| détermine le début d'une transaction. BEGIN est utilisée sous SQL Server. |
| COMMIT [ WORK ]; |
| enregistre les modifications produites par des transactions. |
| ROLLBACK{ [WORK | TO nom_point] }; |
| annule les modifications qui n'ont pas été enregistrées précédemment. |
| SAVEPOINT nom_point; |
| insère un point de sauvegarde dans la liste de transactions, servant en conjonction avec ROLLBACK pour une annulation jusqu'à un point précis. |
La commande SAVEPOINT évite une annulation complète des transactions par la commande ROLLBACK.
Transactions...
SAVEPOINT nom_point
Transactions...
ROLLBACK TO nom_point;
D'ailleurs, une commande spécifique permet de supprimer des points de sauvegardes créés par la commande SAVEPOINT.
RELEASE SAVEPOINT nom_point;
Exemple
SET TRANSACTION;
SAVEPOINT sup1;
DELETE FROM tbl_produit WHERE fabricant = 'AME et Cie';
SAVEPOINT sup2;
DELETE FROM tbl_produit WHERE fabricant = 'EROS';
SAVEPOINT sup3;
DELETE FROM tbl_produit
WHERE num_produit BETWEEN 12045367 AND 12045401;
SAVEPOINT maj;
INSERT INTO tbl_produit SELECT * FROM vue_nouveau_produit;
ROLLBACK TO sup3;
COMMIT;
BEGIN TRANSACTION
USE base_donnee
GO
UPDATE tbl_produit
SET prix = (( prix * 12 ) / 100 ) + prix
WHERE fabricant = 'CACO LOCA'
GO
COMMIT
GO |
Les fonctions SQL permettent d'accomplir différentes actions sur les informations d'une base de données.
Les fonctions d'agrégation accomplissent un calcul sur plusieurs valeurs et retournent un résultat. Elles sont principalement utilisées avec les commandes GROUP BY et SELECT.
Les calculs effectués par ces fonctions consiste à faire sur une colonne, la somme, la moyenne des valeurs, le décompte des enregistrements ou encore l'extraction de la valeur minimum ou maximum.
Hormis la fonction COUNT, les fonctions d'agrégation ne tiennent pas compte des valeurs NULL.
| Fonction |
Description |
| AVG |
retourne la moyenne des valeurs d'un groupe. |
| BINARY_CHECKSUM |
retourne la valeur totale de contrôle binaire calculée à partir d'une ligne d'une table ou d'une liste d'expressions. |
| CHECKSUM |
retourne la valeur de checksum calculée dans une ligne d'une table ou dans une liste d'expressions. |
| CHECKSUM_AGG |
retourne le checksum des valeurs d'un groupe. |
| COUNT |
retourne le nombre d'éléments figurant dans un groupe. |
| COUNT_BIG |
retourne le nombre d'éléments figurant dans un groupe. |
| MAX |
retourne la valeur maximale de l'expression. |
| MIN |
retourne la valeur minimale de l'expression. |
| SUM |
retourne la somme de toutes les valeurs |
| STDEV |
retourne l'écart type de toutes les valeurs de l'expression spécifiée. |
| STDEVP |
retourne l'écart type de remplissage pour toutes les valeurs de l'expression spécifiée. |
| VAR |
retourne la variance de toutes les valeurs de l'expression spécifiée. |
| VARP |
retourne la variance de remplissage pour toutes les valeurs de l'expression spécifiée. |
Exemple
SELECT COUNT(Livre)
FROM Librairie
' retourne
7
SELECT SUM(Prix)
FROM Librairie
' retourne
1 571 |
Les fonctions mathématiques permettent d'effectuer des calculs sur des expressions SQL.
Les fonctions
| Fonction |
| Description |
| ABS(Expression) |
| retourne la valeur absolue de l'expression. |
| CEIL(Expression) |
| retourne le plus petit entier supérieur ou égal à l'expression. SQL Server utilise CEILING(). |
| COS(Expression) |
| retourne le cosinus de l'expression. |
| EXP(Expression) |
| retourne la valeur exponentielle de l'expression. |
| FLOOR(Expression) |
| retourne le plus grand entier inférieur ou égal à l'expression. |
| LN(Expression) |
| retourne le logarithme népérien de l'expression qui doit être un entier strictement positif. |
| LOG(Base, Expression) |
| retourne le logarithme en base Base de l'expression. Base doit être un entier strictement supérieur à 1, et l'expression un entier strictement positif. |
| POWER(Expression, Exposant) |
| retourne la puissance de l'expression (ExpressionExposant). |
| ROUND( Expression , Longueur [ , Fonction ] ) |
| retourne l'arrondi de l'expression à la longueur indiquée et éventuellement à la longueur après la virgule fournie. |
| SIGN(Expression) |
| retourne le signe de l'expression. |
| SIN(Expression) |
| retourne le sinus de l'expression. |
| SQRT(Expression) |
| retourne la racine carrée de l'expression. |
| TAN(Expression) |
| retourne la tangente de l'expression. |
| TO_NUMBER(expression) |
| convertit des chaînes de caractères en valeur numérique. |
Exemple
SELECT valeur,
SIN(valeur),
COS(valeur),
TAN(valeur)
FROM tbl_angle;
SELECT SQRT(POWER(AB, 2) + POWER(BC, 2)) AS AB
FROM tbl_triangle |
Les fonctions sur les chaînes de caractères permettent de manipuler les chaînes de caractères.
Diverses données textuelles provenant d'une ou plusieurs colonnes peuvent être combinées en une unique chaîne de caractères. Par exemple, le nom et le prénom d'une personne pourraient être concaténés afin de donner une seule valeur.
Les fonctions
| Fonction |
| Description |
| CONCAT (chaine1, chaine2) |
| concatène la première chaîne à la seconde. CONCAT correspond à chaine || chaine2 sous Oracle. |
| TRANSLATE (nom_colonne, valeur1, valeur2) |
| recherche la première valeur dans la colonne spécifiée et substitue toutes les occurrences de valeur1 par celles de valeur2. |
| REPLACE (nom_colonne, valeur1, valeur2) |
| remplace toutes les occurrences de la première valeur dans la colonne spécifiée par celles de la seconde valeur. |
| UPPER (chaine) |
| convertit la chaîne de caractères en lettres majuscules. |
| LOWER (chaine) |
| convertit la chaîne de caractères en lettres minuscules. |
| SUBSTR(nom_colonne, position_départ, longueur) |
| retourne une sous-chaîne de caractères extraite de la colonne spécifiée à partir d'une position de départ et jusqu'à une certaine longueur. Pour SQL Server, la fonction se dénomme SUBSTRING. |
| INSTR(nom_colonne, jeu_caractères, position_départ, nb_occurrence) |
| recherche le jeu de caractères dans une colonne et retourne la position de la première lettre du jeu de caractères. Pour SQL Server, il est possible d'utiliser CHARINDEX ou PATINDEX (voir MSDN). |
| LTRIM(nom_colonne, jeu_caractères) |
| supprime les caractères situés à la gauche de la chaîne de caractères. |
| RTRIM(chaine, jeu_caractères) |
| supprime les caractères situés à la droite de la chaîne de caractères. |
DECODE(nom_colonne, valeur1, valeur2,
[valeur1, valeur2, valeur_défaut]) |
| recherche les valeurs valeur1 dans la colonne et les remplace par les valeurs valeur2 et toutes les autres valeurs sont remplacées par la valeur par défaut. |
| LENGTH(chaine) |
| retourne la longueur de la chaîne de caractères. |
| NVL(nom_colonne, valeur) |
| remplace les valeurs nulles de la colonne par une valeur de substitution. |
| LPAD(nom_colonne, longueur, caractère) |
| remplit à gauche des valeurs de la colonne un certain nombre du caractère indiqué pour arriver à la longueur voulue. |
| RPAD(nom_colonne, longueur, caractère) |
| remplit à droite des valeurs de la colonne un certain nombre du caractère indiqué pour arriver à la longueur voulue. |
| ASCII(jeu_caractères) |
| retourne la valeur ASCII d'un jeu de caractères indiqué. |
| TO_CHAR(expression) |
| convertit des valeurs numériques en chaînes de caractères. |
Exemple
SELECT CONCAT(CONCAT(UPPER(nom), ' ')), prenom)
FROM tbl_client
WHERE montant_vente >= 1000;
SELECT LPAD(nom, 15, '.'), RPAD(prenom, 15, '.')
FROM tbl_client
WHERE date_naissance = SYSDATE;
SELECT num_client, NVL(email, 'adresse@email.com')
FROM tbl_client
WHERE email = NULL;
-- SQL Server
SELECT CHARINDEX('e', 'Chaîne de caractères', 0) value FROM table
SELECT PATINDEX('c%t%s','Chaîne de caractères') value FROM table
-- Oracle
SELECT INSTR('Chaîne de caractères', 'e', 0) value FROM table |
Les dates et les heures possèdent une place importante dans des applications SQL, dans la mesure ou elles permettent d'ajouter une dimension temporelle aux enregistrements d'une base de données.
Dans de nombreuses applications SQL, des données temporelles sont associées à diverses informations lors de leur saisie manuelle ou automatique.
|
Par exemple, un nouvel abonné représenté par des champs tels que le nom, le prénom et l'adresse postale entre autres, pourrait également saisir une date de naissance par l'intermédiaire d'un formulaire, puis au moment de l'ajout de l'enregistrement dans la base de données, une date et éventuellement une heure seraient insérées automatiquement dans la ligne de données afin de conserver un historique des demandes d'abonnement.
|
| Table d'abonnés |
| Num_Abonne |
| Date_Abonnement |
| Nom |
| Prenom |
| Date_Naissance |
| Adresse |
| ... |
|
|
En outre, les dates et les heures peuvent permettre de sélectionner des jeux d'enregistrements avec des requêtes contenant des conditions temporelles. Ainsi, un commercial aurait la possibilité de consulter l'ensemble des individus ayant souscrit un abonnement dans un intervalle de temps précis.
Le format des dates et des heures dépend souvent des différentes implémentations SQL. Néanmoins, des formats standardisés ont été spécifiés afin d'éviter une trop grande hétérogénéité.
| Format |
| Description |
| AAAA-MM-JJ |
| représente un format de date respectivement, année-mois-jour, avec un intervalle allant de 0001-01-01 jusqu'à 9999-12-31. |
| HH:MN:SS.nnn |
| représente un format horaire respectivement, heures:minutes:secondes, allant de 00:00:00 jusqu'à 23:59:61.999 |
Le standard ANSI prévoit trois types de données principaux de date et d'heure. D'autres types peuvent exister selon les implémentations.
| Type de données |
| Description |
| DATE = AAAA-MM-JJ |
| stocke une date (ex: 10/01/2002). |
| TIME = HH:MN:SS.nnn |
| stocke une heure (ex: 10:12:42) |
| TIMESTAMP = AAAA-MM-JJ HH:MN:SS.nnn |
| stocke une valeur de date et d'heure combinées. |
Les serveurs SQL tels que SYBASE et SQL Server utilisent les types de données datetime combinant les formats de date et d'heure, ainsi que SMALLDATETIME identique au précédent hormis que l'intervalle de date autorisé est plus restreint.
Les types de données de date et d'heure sont divisibles en plusieurs éléments distincts.
| Elément |
| Description |
| YEAR = AAAA |
| stocke une année, allant de 0001 jusqu'à 9999. |
| MONTH = MM |
| stocke le mois, allant de 01 jusqu'à 12 |
| DAY = JJ |
| stocke le jour d'une date, allant de 01 jusqu'à 31. |
| HOUR = HH |
| stocke les heures, allant de 00 jusqu'à 23 |
| MINUTE = MN |
| stocke les minutes, allant de 00 jusqu'à 59. |
| SECONDE = SS.nnn |
| stocke les secondes, allant de 00 jusqu'à 61.999 |
Diverses commandes et fonctions permettent une manipulation aisée des dates et des heures dans des applications SQL.
Les fonctions de date et d'heure permettent diverses manipulations sur des informations temporelles.
La récupération de la date en cours est possible par l'intermédiaire de la fonction GETDATE sous SQL Server et Sybase alors que Oracle utilise la fonction SYSDATE.
SELECT GETDATE() AS Date, nom_champ, ...
FROM nom_table
SELECT SYSDATE AS Date, nom_champ, ...
FROM nom_table
Les heures et les dates sont décomposables en plusieurs valeurs telles que les secondes, les minutes, les heures, le jour, le mois et l'année entre autres à partir d'une valeur datetime ou TIMESTAMP.
SELECT DATEPART (yyyy, GETDATE()) FROM nom_table
SELECT { fn YEAR ( { fn CURDATE() } ) } FROM nom_table
Dans cet exemple, les deux syntaxes respectivement sous SQL Server et Oracle, retournent l'année de la date courante.
Il est également possible d'effectuer des calculs sur des dates et des heures comme des additions ou des soustractions.
SELECT DATEADD(mm, 3, GETDATE()) FROM nom_table
SELECT SYSDATE + INTERVAL '3' MONTH FROM nom_table
Ces exemples permettent d'ajouter trois mois à la date courante. Pour ajouter un jour, il suffit sous SQL Server de modifier la partie mm par dd et MONTH par DAY pour Oracle.
SELECT DATEADD(dd, 7, GETDATE()) FROM nom_table
SELECT SYSDATE + INTERVAL '7' DAY FROM nom_table
Sous Oracle, il est possible d'additionner ou de soustraire directement un nombre entier représentant des jours, à une date.
SELECT SYSDATE + 7 FROM nom_table
D'autres éléments de date et d'heure peuvent être ajoutés ou extraits par le même biais sous Oracle.
//soustrait une heure de la date courante
SELECT SYSDATE - 1/24 FROM nom_table
//soustrait 10 minutes de la date courante
SELECT SYSDATE - 1/144 FROM nom_table
Les fonctions
| Fonctions SQL Server |
| Description |
| DATEADD ( partie_date, nombre, date ) |
| ajoute un nombre représentant une partie de date à la date spécifiée. |
| DATEDIFF ( partie_date , date_départ , date_fin ) |
| soustrait la date de fin de celle de départ en fonction de la partie spécifiée. |
| DATENAME ( partie_date , date ) |
| retourne une chaîne de caractères déterminée à partir de la date et de la partie indiquées. |
| DATEPART ( partie_date , date ) |
| retourne la partie indiquée par le premier argument à partir d'une date. |
| DAY ( date ) |
| retourne un entier représentant le jour à partir de la date spécifiée. |
| GETDATE() |
| retourne la date et l'heure courantes. |
| GETUTCDATE() |
| retourne la date et l'heure UTC (Universal Time Coordinates) courantes. |
| MONTH ( date ) |
| retourne le mois sous forme d'un entier à partir d'une date spécifiée. |
| YEAR ( date ) |
| retourne l'année sous forme d'une entier à partir de la date spécifiée. |
| Fonctions Oracle |
| Description |
| ADD_MONTHS(date, nb_mois) |
| ajoute un nombre de mois spécifié à une date. |
| { fn CURDATE ( [ expression_date ] ) } |
| retourne la date courante. |
| CURRENT_DATE |
| retourne la date courante. |
| CURRENT_TIME |
| retourne l'heure courante. |
| CURRENT_TIMESTAMP |
| retourne la date et l'heure courantes. |
| { fn CURTIME ( [ expression_date ] ) } |
| retourne l'heure courante. |
| { fn DAYNAME ( [ expression_date ] ) } |
| retourne le nom du jour de la semaine. |
| { fn DAYOFMONTH ( [ expression_date ] ) } |
| retourne le jour du mois sous forme d'entier. |
| { fn DAYOFWEEK ( [ expression_date ] ) } |
| retourne le jour de la semaine sous forme d'un entier. |
| { fn DAYOFYEAR ( [ expression_date ] ) } |
| retourne le jour d'une année sous forme d'un entier. |
| HOUR ( expression_temps ) |
| retourne l'heure à partir d'une expression horaire. |
| INTERVAL ( valeur partie_date ) |
| spécifie un intervalle de temps pour effectuer des opérations. |
| LAST_DAY ( date ) |
| retourne une date qui représente le dernier jour du mois dans lequel la date s'est produite. |
| { fn MINUTE ( expression_temps ) } |
| retourne les minutes à partir d'une expression horaire. |
| { fn MONTH ( expression_temps ) } |
| retourne le mois à partir d'une expression horaire. |
| { fn MONTHNAME ( expression_temps ) } |
| retourne le nom d mois à partir d'une expression horaire. |
| MONTHS_BETWEEN ( date_1, date_2 ) |
| retourne le nombre de mois entre les deux valeurs de date. |
| NEXT_DAY ( date, chaîne ) |
| retourne la date du premier jour de la semaine correspondant à la chaîne de caractères spécifiée. |
| NOW |
| retourne la date et l'heure courante comme une valeur de TIMESTAMP. |
| ROUND ( date, format ) |
| retourne la date spécifiée selon le format fourni. |
| { fn SECOND ( expression_temps ) } |
| retourne le nombre de secondes à partir d'une expression horaire. |
| SYSDATE |
| retourne la date et l'heure courantes. |
| TIMESTAMPADD ( intervalle, nombre, date ) |
| retourne le résultat de l'addition d'une date à un nombre entier selon un intervalle spécifié (SQL_TSI_FRAC_SECOND, SQL_TSI_SECOND, SQL_TSI_MINUTE, SQL_TSI_HOUR, SQL_TSI_DAY, SQL_TSI_WEEK, SQL_TSI_MONTH, SQL_TSI_QUARTER, SQL_TSI_YEAR). |
| TIMESTAMPDIFF ( intervalle, nombre, date ) |
| retourne le résultat de la soustraction d'une date et d'un nombre entier selon un intervall spécifié (voir ci-dessus). |
| TO_DATE ( chaîne ) |
| convertit une chaîne de caractères en une valeur de date et d'heure valide. |
| TRUNC ( date, format ) |
| retourne le résultat d'une troncature d'une date selon un format spécifié. |
| { fn WEEK ( expression_date ) } |
| retourne la semaine d'une année sous la forme d'un entier. |
| { fn YEAR ( expression_date ) } |
| retourne une année sous la forme d'un entier. |
Exemple
SELECT TO_CHAR(ADD_MONTHS(debut_abonnt, 6))
AS 'Fin abonnement', num_abonnt
FROM tbl_abonne
WHERE date_abonnt = SYSDATE - (INTERVAL '5' MONTH);
USE base
GO
CREATE TABLE tbl_employees
(
num_employe NUMERIC(9, 0) PRIMARY KEY,
date_embauche DATETIME DEFAULT GETDATE(),
nom VARCHAR(40) NOT NULL,
prenom VARCHAR(20) NOT NULL,
adresse VARCHAR(255) NOT NULL,
code_postal VARCHAR(5) NOT NULL
ville VARCHAR(30) NOT NULL,
telephone VARCHAR(10) NULL,
email VARCHAR(50) NULL
)
GO |
Les formats de date sous Oracle permettent de formater des valeurs de date et d'heure selon un masque précis.
Day, Month DD,YYYY HH24:MI:SS
Friday, December 28, 2001 23:16:41
DD/MM/YYYY HH:MI:SS AM
28/12/2001 11:16:41 AM
Les formats de date et d'heure peuvent être utilisés en argument avec les fonctions ROUND et TRUNC.
ROUND ( '10/12/2001', 'YEAR')
TRUNC ( '10/12/2001', 'dd')
La fonction INTERVAL peut également comporter de tels éléments afin d'indiquer le type de la valeur fournie.
SELECT id_cmd, date_cmd + INTERVAL '30' DAY FROM commandes;
| Format |
Description |
| SCC | CC |
représente le siècle. Le "S" indique les dates BC (Before Christ) avec "-". |
| YEAR | SYEAR |
représente une année. |
| YYYY | SYYYY |
représente une année sur quatre chiffres. |
| IYYY |
représente une année sur quatre chiffres, basée sur le standard ISO. |
| YYY | YY | Y |
représente respectivement les trois, deux ou un chiffre(s) d'une année. |
| IYY | IY | I |
représente respectivement les trois, deux ou un chiffre(s) d'une année basée sur le standard ISO. |
| Y,YYY |
représente une année avec une virgule. |
| q |
représente le trimestre d'une année (1-4). |
| MM |
représente le mois sur deux chiffres (1-12). |
MONTH
Month
month |
représente le nom littéral du mois (JANUARY-DECEMBER). |
MON
Mon
mon |
représente une abréviation littérale du nom de mois (JAN-DEC). |
| WW |
représente le numéro de la semaine sur une année (1-53). |
| IW |
représente le numéro de la semaine basé sur le standard ISO (1-52/53). |
| W |
représente le numéro de la semaine d'un mois (1-5). |
| DDD |
représente le numéro du jour sur une année (1-365). |
| dd |
représente le numéro du jour sur un mois (1-31). |
| D |
représente le numéro du jour sur une semaine (1-7). |
DAY
Day
day |
représente le nom littéral du jour (SUNDAY-SATURDAY). |
DY
Dy
dy |
représente le nom littéral abrégé du jour (SUN-SAT)). |
| AM | PM |
représente l'indicateur méridien. |
| A.M. | P.M. |
représente l'indicateur méridien avec des périodes. |
| HH | HH12 |
représente l'heure d'une journée sur douze heures (1-12). |
| HH24 |
représente l'heure d'une journée sur vingt-quatre heures (0-23). |
| MI |
représente les minutes (0-59). |
| RM |
représente le numéro du mois sous forme de chiffres romains. |
| RR |
représente les deux chiffres d'une année pour les années dans d'autres pays. |
| SS |
représente les secondes (0-59). |
| SSSSS |
représente les secondes sur vingt-quatre heures (0-86399). |
| - / . ; : "texte" |
représente les signes de ponctuation et les guillemets pour du texte permis. |
Les formats de date et d'heure sous SQL Server peuvent prendre quasiment n'importe quelle forme à l'aide des éléments cités dans le tableau ci-dessous.
dddd, MMMM dd,yyyy hh:mm:ss.ffff tt
Friday, December 28, 2001 11:16:41.0021 AM
dd/MM/yyyy HH:mm:ss
28/12/2001 23:16:41
| Format |
Description |
| yyyy |
représente une année sur quatre chiffres. |
| yy |
représente une année sur deux chiffres. |
| qq | q |
représente le trimestre d'une année. |
| MM | M |
représente le mois sur deux chiffres. |
| MMMM |
représente le nom littéral du mois. |
| MMM |
représente le nom littéral abrégé du mois. |
| dd | d |
représente le jour sur deux chiffres. |
| dddd |
représente le nom littéral du jour de la semaine. |
| ddd |
représente le nom littéral abrégé du jour de la semaine |
| hh | h |
représente l'heure d'une journée sur douze heures. |
| HH | H |
représente l'heure d'une journée sur vingt-quatre heures. |
| mm | m |
représente les minutes. |
| ss | s |
représente les secondes. |
| f |
représente les fractions de secondes. |
| tt |
représente l'indicateur méridien AM/PM. |
Les parties de date pour les fonctions DATEADD, DATEDIFF, DATENAME et DATEPART peuvent être utilisées dans leur forme littérale comme dans leurs abréviations.
| Partie de date |
Abréviations |
Description |
| year |
yy, yyyy |
Année |
| quart |
qq, q |
Trimestre |
| month |
mm, m |
Mois |
| dayofyear |
dy, y |
Jour de l'année (1 - 365) |
| day |
dd, d |
Jour |
| weeek |
wk, ww |
Semaine |
| weekday |
dw |
Jour de la semaine |
| hour |
hh |
Heures |
| minute |
min |
Minutes |
| second |
ss, s |
Secondes |
| millisecond |
ms |
Millisecondes |
Les requêtes composées permettent de lier différentes requêtes par l'intermédiaire d'opérateurs spéciaux.
SELECT tab1.nom_champ FROM nom_table AS tab1
UNION | UNION ALL | INTERSECT | EXCEPT
SELECT tab2.nom_champ FROM nom_table AS tab2
[ORDER BY];
L'opérateur UNION permet de récupérer l'ensemble des enregistrements retournés par les deux requêtes. Les doublons ne sont pas pris en compte.
SELECT tab1.nom_champ
FROM nom_table AS tab1
UNION
SELECT tab2.nom_champ
FROM nom_table AS tab2
Evidemment, ce genre de requête composée ne s'applique qu'à des champs sélectionnés identiques.
L'opérateur UNION ALL contrairement à l'opérateur précédent retourne tous les enregistrements y compris les doublons.
SELECT tab1.nom_champ
FROM nom_table AS tab1
UNION ALL
SELECT tab2.nom_champ
FROM nom_table AS tab2
L'opérateur INTERSECT [ ALL ] retourne uniquement les enregistrements communs de la première requête à ceux de la seconde.
SELECT tab1.nom_champ
FROM nom_table AS tab1
INTERSECT
SELECT tab2.nom_champ
FROM nom_table AS tab2
L'opérateur EXCEPT ou MINUS retourne seulement les enregistrements différents de la première table à ceux de la seconde table.
SELECT tab1.nom_champ
FROM nom_table AS tab1
EXCEPT
SELECT tab2.nom_champ
FROM nom_table AS tab2
La clause ORDER BY applicable à l'ensemble des requêtes, permet d'ordonner les réponses selon une des colonnes à sélectionner.
SELECT tab1.nom_champ, tab1.nom_champ2
FROM nom_table AS tab1
EXCEPT
SELECT tab2.nom_champ, tab2.nom_champ2
FROM nom_table AS tab2
ORDER BY 2;
Exemple
SELECT num_cmd FROM tbl_vente_magasin WHERE date = SYSDATE - 7
UNION
SELECT num_cmd FROM tbl_vente_internet WHERE date = SYSDATE - 7;
SELECT * FROM tbl_produit
UNION ALL
SELECT * FROM vue_nouv_prod
WHERE accord = 'true'
SELECT nom, prenom FROM tbl_employe
INTERSECT
SELECT nom, prenom FROM tbl_client
SELECT num_produit, designation, quantite FROM tbl_stock
MINUS
SELECT num_produit, designation, quantite
FROM tbl_commande WHERE date_cmd = SYSDATE - 2; |
Les procédures stockées contiennent du code SQL compilé, permettant d'exécuter des requêtes lourdes ou des instructions régulièrement utilisées sur des bases de données.
Les procédures stockées sont conservées dans la base de données dans une forme exécutable et sont capables d'appeler d'autres procédures ou fonctions comme d'être appelées par d'autres programmes.
La structure modulaire de telles procédures permet de concevoir des petites unités programmatiques indépendantes, donc plus rapides à charger en mémoire et partant à exécuter dans une base de données.
A l'instar des procédures des langages de programmation, outre qu'elles soient composées de diverses instructions, les procédures stockées sont capables de recevoir des paramètres d'entrée et de retourner des valeurs en sortie.
La création des procédures stockées s'effectue par l'intermédiaire de l'instruction CREATE PROCEDURE.
Syntaxe pour SQL Server
CREATE PROC [ EDURE ] nom_procedure [ ; nombre ]
[ { @parametre type_donnee }
[ VARYING ] [ = valeur_defaut ] [ OUTPUT ]
] [ ,...n ]
[ WITH
{ RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ]
[ FOR REPLICATION ]
AS instructions_SQL...
GO |
La clause VARYING, applicable aux paramètres de type CURSOR, indique le jeu de résultats pris en charge.
La clause OUTPUT permet de retourner la valeur aux instructions appelantes.
L'instruction WITH RECOMPILE spécifie que la procédure est recompilée à l'exécution sans utiliser le cache pour le plan de la procédure.
L'option RECOMPILE est généralement utilisée pour des valeurs temporaires ou atypiques sans remplacer le plan d'exécution placé en mémoire cache.
La clause WITH ENCRYPTION indique un cryptage de l'entrée de la table syscomments contenant le texte de l'instruction CREATE PROCEDURE. L'argument ENCRYPTION permet d'éviter la publication de la procédure dans le cadre de la réplication SQL Server.
La clause FOR REPLICATION indique que la procédure stockée doit être exécutée lors de la modification de la table concernée par un processus de réplication.
La clause AS indique les actions entreprises par la procédure.
L'instruction GO signale la fin d'un jeu d'instructions.
Syntaxe pour Oracle
CREATE [OR REPLACE] PROCEDURE [schema .] procedure
[ ( argument [ IN | OUT | IN OUT ] [ NOCOPY ] type_donnee
[, argumentN [ IN | OUT | IN OUT ] [ NOCOPY ] type_donnee] ) ]
[ AUTHID { CURRENT_USER | DEFINER }]
{ IS | AS }
{ instruction_pl/sql | instruction_langage }; |
La commande OR REPLACE recrée la procédure stockée si elle existe déjà.
La clause OUT permet de retourner la valeur aux instructions appelantes.
La clause IN est utilisée pour spécifier une valeur pour l'argument en appelant la procédure.
La clause AS (dépréciée) ou IS indique les actions entreprises par la procédure.
Les procédures stockées peuvent être appelées au moyen de l'instruction EXECUTE (SQL Server) ou CALL (Oracle) à partir d'une autre procédure ou d'un lot d'instructions. SQL Server peut utiliser une abréviation EXEC.
-- SQL Server
EXECUTE Procedure @Parametre = Valeur, ..., @ParametreN = ValeurN
-- Oracle
CALL Procedure(Valeur, ..., ValeurN) |
Exemple
-- Instruction pour SQL Server
CREATE PROCEDURE Ajout_Enregistrement
@proc_ID CHAR(10),
@proc_Nom VARCHAR(20),
@proc_Prenom VARCHAR(20),
@proc_CP CHAR(5)
AS
INSERT INTO Fiche_Personne
(ID, Nom, Prenom, CP)
VALUES (@proc_ID, @proc_Nom, @proc_Prenom, @proc_CP)
GO
-- Instruction pour Oracle
CREATE PROCEDURE Ajout_Enregistrement (
proc_ID IN CHAR(10),
proc_Nom IN VARCHAR(20),
proc_Prenom IN VARCHAR(20),
proc_CP IN CHAR(5)
)
IS
BEGIN
INSERT INTO Fiche_Personne
(ID, Nom, Prenom, CP)
VALUES (proc_ID, proc_Nom, proc_Prenom, proc_CP)
END;
-- Utilisation
-- Sous SQL Server
execute Ajout_Enregistrement '0000075036', 'ANTONIN', 'Jacques', '93300'
-- Sous Oracle
call Ajout_Enregistrement('0000075036', 'ANTONIN', 'Jacques', '93300'); |
Les déclencheurs (Triggers) sont des procédures stockées appartenant à une table précise et s'exécutant lorsqu'une action spécifique se produit sur la table concernée.
Le déclenchement d'une telle procédure s'effectue subséquemment à une instruction de manipulation de données (DML) comme INSERT, DELETE ou UPDATE.
Il existe donc trois types de déclencheurs, sur insertion, sur mise à jour et sur suppression.
Une table peut comporter plusieurs déclencheurs d'un type donné, à condition que chacun possède un nom différent. Cependant, un déclencheur donné ne peut être assigné qu'à une seule et unique table tout en s'appliquant à la fois, à l'insertion, la mise à jour et la suppression d'enregistrements sur la table en question.
Une table ne peut posséder qu'un seul déclencheur INSTEAD OF d'un type donné.
Les déclencheurs se produisent soit après (AFTER), soit avant (BEFORE) soit à la place (INSTEAD OF) d'une action DML.
Un déclencheur sur INSERT s'exécute à chaque opération d'insertion lancée par l'utilisateur ou par un programme. Lors d'une insertion, l'enregistrement est inséré à la fois dans la table cible est dans une table temporaire dénommée inserted. Une telle table peut permettre de vérifier la cohérence des enregistrements.
Un déclencheur sur DELETE s'exécute à chaque opération de suppression lancée par l'utilisateur ou un programme. Lors d'une suppression, l'enregistrement est supprimé physiquement de la table cible et l'insère dans une table temporaire dénommée deleted. Cela peut permettre de récupérer l'enregistrement supprimé.
Un déclencheur sur UPDATE s'exécute à chaque opération de mise à jour lancée par l'utilisateur ou par un programme. Lors d'une mise à jour, l'ancien enregistrement est supprimé et inséré dans la table temporaire deleted, tandis que le nouveau est inséré à la fois dans la table cible et dans la table inserted.
La suppression des déclencheurs s'effectue par l'intermédiaire de l'instruction DROP.
DROP TRIGGER nom_déclencheur [ , nom_déclencheurN ]
La modification des déclencheurs s'effectue par l'intermédiaire de l'instruction ALTER. La syntaxe complète de la commande ALTER TRIGGER est en fait identique dans le cas d'Oracle ou de SQL Server à celle de CREATE TRIGGER.
ALTER TRIGGER nom_déclencheur_existant
ON nom_table
FOR INSERT, UPDATE, DELETE
AS instruction_SQL...
Tous les déclencheurs (ALL) ou certains peuvent être activés (ENABLE) ou désactivés (DISABLE) au moyen de l'instruction ALTER TABLE.
ALTER TABLE table
{ ENABLE | DISABLE } TRIGGER
{ ALL | nom_déclencheur [ , nom_déclencheurN ] }
La syntaxe des déclencheurs sous Oracle peut être plus ou moins complexe.
CREATE [ OR REPLACE ] TRIGGER propriétaire.nom_déclencheur
AFTER | BEFORE { [ INSERT [ OR DELETE
[ OR UPDATE OF nom_colonne,...,nom_colonneN ] ] ] }
ON propriétaire.nom_table
FOR EACH ROW nom_procédure (argument...argumentN); |
La seconde syntaxe se révèle bien plus abconse, puisqu'elle intègre non seulement les déclencheurs DML mais également d'autres types de déclencheurs basés sur des commandes DDL ou DATABASE.
En outre, pour les déclencheurs DML, des clauses spécifiques aux vues apparaissent, ainsi que la clause REFERENCING.
CREATE [ OR REPLACE ] TRIGGER [ schéma. ] nom_déclencheur
{
AFTER | BEFORE | INSTEAD OF
}
{
{
[ INSERT
[ OR DELETE
[ OR UPDATE [ OF nom_colonne [, nom_colonneN ] ] ] ] ]
}
ON
{
{ [ schéma. ] nom_table }
|
{ [ NESTED TABLE colonne_emboîtée OF ] [ schéma . ] nom_vue }
}
{
[ REFERENCING ]
{
[ OLD [ AS ] ancienne_colonne
| NEW [ AS ] nouvelle_colonne
| PARENT [ AS ] colonne_parente ]
}
}
[ FOR EACH ROW ] instruction_SQL;
}
|
{
{
{ Evénement_DDL [ OR EvénementN_DDL ] }
|
{ Evénement_Base_Données [ OR EvénementN_Base_Données ]
}
ON
{
{ [ schéma. ] SCHEMA } | DATABASE
}
WHEN ( Condition )
{ instruction_PL/SQL | instruction_procédure };
} |
La commande OR REPLACE recrée le déclencheur s'il existe déjà.
La clause BEFORE indique que le déclencheur doit être lancé avant l'exécution de l'événement.
La clause AFTER indique que le déclencheur doit être lancé après l'exécution de l'événement.
Les instructions INSERT et DELETE indique au déclencheur de s'exécuter lors respectivement d'une insertion ou d'une suppression dans la table.
La clause UPDATE OF indique que le déclencheur doit être lancé lors de chaque mise à jour d'une des colonnes spécifiées. Si elle est omise, n'importe quelle colonne de la table modifiée provoque le décle,chement du Trigger.
La clause ON désigne le nom de la table associé à son schéma pour lequel le déclencheur a été spécifiquement créé.
La clause FOR EACH ROW désigne le déclencheur pour être un déclencheur de ligne. Oracle lance un déclencheur de ligne une fois pour chaque ligne qui est affectée par l'instruction de déclenchment. Si la clause est omise, le déclencheur est un déclencheur d'instruction. Oracle lance un déclencheur de d'instructionune fois seulement lorsque l'instruction déclenchante est émise si la contrainte du déclencheur optionnelle est rencontrée.
La clause REFERENCING permet de spécifier des noms de corrélation. Il est possible d'utiliser les noms de corrélation dans des blocs d'instructions PL/SQL et dans la condition WHEN d'une déclencheur de ligne pour se référer spécifiquement à des valeurs anciennes et nouvelles de la ligne courante. Les noms de corrélation par défaut sont OLD et NEW. Si le déclencheur de ligne est associé à une table nommée OLD ou NEW, l'utilisation de cette clause permet de spécifier des noms de corrélations différents afin d'éviter une confusion entre les noms de table et les noms de corrélation.
Si le déclencheur est défini sur une table imbriquée, OLD et NEW se référent à la ligne de la table imbriquée, et PARENT se référe à la ligne courante de la table parente.
Si le déclencheur est défini sur une table ou une vue, OLD et NEW se référe aux instances d'objet.
La clause REFERENCING n'est pas valide avec les déclencheurs INSTEAD OF sur les événements DDL de création.
Pour de plus amples renseignements consulter la documentation d'Oracle.
Exemple
-- Premier exemple
CREATE OR REPLACE TRIGGER declencheur_suppression
AFTER DELETE ON tbl_1
FOR EACH ROW
WHEN (1 = 1)
DECLARE action_utilisateur VARCHAR2(50);
BEGIN
SELECT user INTO action_utilisateur
FROM DUAL;
INSERT INTO delete_log
VALUES ('tbl_1',action_utilisateur,TO_CHAR(SYSDATE, 'DD/MON/YYYY'),
TO_CHAR(SYSDATE, 'HH24:MI:SS'));
END;
-- Second exemple
CREATE TABLE tbl_1 (col_a INTEGER, col_b CHAR(20));
CREATE TABLE tbl_2 (col_c CHAR(20), col_d INTEGER);
CREATE TRIGGER declencheur_insertion
AFTER INSERT ON tbl_1
FOR EACH ROW
WHEN (NEW.col_a <= 10)
BEGIN
INSERT INTO tbl_2 VALUES(:NEW.col_b, :NEW.col_a);
END; |
Le premier exemple crée un déclencheur qui insère un champ log à l'intérieur d'une table, pour chaque ligne supprimée dans la table spécifiée.
Le second exemple crée un déclencheur qui insére un enregistrement à l'intérieur de la seconde table lorqu'une opération d'insertion s'est accomplie dans la première table. Le déclencheur vérifie si le nouvel enregistrement possède un premier composant inférieur ou égal à 10 et si c'est le cas, inverse les enregistrements à l'intérieur de la seconde table.
Les variables spéciales NEW et OLD sont disponibles pour se référer respectivement à des nouveaux ou d'anciens enregistrements. Les deux points (:) précédent NEW et OLD dans VALUES sont dans ce cas obligatoires, par contre dans la clause conditionnelle WHEN, ils doivent être omis.
Les déclencheurs sous SQL Server peuvent prendre deux formes distinctes selon l'inclusion de l'instruction DELETE.
La première forme permet de construire des déclencheurs des trois types possibles.
CREATE TRIGGER nom_déclencheur
ON { nom_table | nom_vue }
[ WITH ENCRYPTION ]
{
{ { FOR | AFTER | INSTEAD OF } { [ INSERT ] [,] [ UPDATE ] [,] [ DELETE ] }
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS
}
instruction_SQL...
}
} |
La syntaxe ci-dessous ne permet la création que de deux types de déclencheur. Néanmoins, des structures conditionnelles donnent la possibilité de tester les modifications apportées aux colonnes spécifiées.
CREATE TRIGGER nom_déclencheur
ON { nom_table | nom_vue }
[ WITH ENCRYPTION ]
{
{ { FOR | AFTER | INSTEAD OF } { [ INSERT ] [,] [ UPDATE ]
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS
[ { IF UPDATE ( nom_colonne )
[ { AND | OR } UPDATE ( nom_colonne ) ]
[ ...n ]
|
IF ( COLUMNS_UPDATED()
{ Operateur_Niveau_Bit } Mise_Jour_Masque_Bit )
{ = | > } Colonne_Masque_Bit [ ...n ]
} ]
instruction_SQL...
}
} |
La clause ON désigne la table ou la vue concernées par le déclencheur.
La clause WITH ENCRYPTION indique que SQL Server crypte les entrées syscomments qui contiennent le texte de l'instruction CREATE TRIGGER.
La clause for indique le déclenchement du Trigger pour un type d'événement.
La clause AFTER indique le déclenchement du Trigger suite à un type d'événement.
La clause INSTEAD OF indique un exécution des instructions du Trigger à la place de celles normalement produites par l'événement déclencheur.
Les instructions INSERT, UPDATE et DELETE représentent chacun un type de déclencheur respectivement sur une insertion, une mise à jour et une suppression.
La clause WITH APPEND indique la nécesité d'ajouter un déclencheur supplémentaire d'un type existant.
La clause NOT FOR REPLICATION indique que le déclencheur ne doit pas être exécuté lors de la modification de la table concernée par un processus de réplication.
La clause IF UPDATE exécute des tests pour une opération INSERT ou UPDATE sur une ou plusieurs colonnes spécifiées à la suite de l'instruction. Les colonnes à tester, peuvent être articulées autour d'un opérateur AND ou OR afin d'effectuer un test conditionnel sur l'une ou/et l'autre des colonnes. La clause retourne une valeur booléenne.
La clause colUMNS_UPDATED retourne un modèle de bit de type varbinary indiquant les colonnes ayant subi des modifications suite à un test dans un déclencheur de type INSERT ou UPDATE uniquement.
IF (COLUMNS_UPDATED() & 15) = 15
IF (COLUMNS_UPDATED() & 15) > 0
La valeur 15 suivant l'opérateur de niveau de bit & représente les cinq premières colonnes d'un tableau. Le signe égal = permet de vérifier dans ce cas si les cinq colonnes ont été modifiées. Dans l'autre exemple, le signe supérieur à > est spécifié, il s'agit ici d'une vérification sur l'une ou l'autre des cinq colonnes indiquées.
Exemple
-- Premier exemple
CREATE TABLE tbl_produit ( nom VARCHAR(20), identificateur INTEGER )
GO
INSERT tbl_produit
SELECT 'dentifrice', 1 UNION
SELECT 'savon', 2 UNION
SELECT 'savon', 0 UNION
SELECT 'brosse à dent', 3 UNION
SELECT 'brosse à dent', 0 UNION
SELECT 'rasoir', 4 UNION
SELECT 'mousse à raser', 5 UNION
SELECT 'serviette', 6 UNION
SELECT 'serviette', 0 UNION
SELECT 'peigne', 7 UNION
SELECT 'brosse à cheveux' 8
GO
CREATE TRIGGER declencheur_suppression
ON tbl_produit FOR DELETE
AS
SELECT nom AS "Lignes à supprimer"
FROM deleted
GO
CREATE TRIGGER declencheur_insteadof
ON tbl_produit INSTEAD OF DELETE
AS
DELETE tbl_produit
FROM tbl_produit INNER JOIN deleted
ON tbl_produit.nom = deleted.nom
WHERE tbl_produit.identificateur = 0
GO
DELETE tbl_produit
WHERE nom IN ('brosse à dent', 'serviette', 'savon')
GO
SELECT * FROM tbl_produit
GO
DROP TABLE tbl_produit
-- Second exemple
CREATE TRIGGER envoi_email
ON nom_table
FOR INSERT, UPDATE, DELETE
AS
EXEC master.dbo.xp_sendmail @recipients = 'Administrateur',
@message = 'Attention une modification a été
effectuée dans la table : nom_table.',
@subject = 'Modification sur une table.'
GO
-- Troisième exemple
CREATE TRIGGER avertissement
ON nom_table
FOR INSERT, UPDATE, DELETE
AS
RAISERROR ('Attention une modification a été effectuée dans la table', 16, 10)
GO |
Le premier exemple met en exergue le processus permettant de faire appel à différents types de déclencheurs au sein d'une table. Le premier déclencheur FOR DELETE s'exécute lors d'une suppression en sélectionnant les lignes supprimées à partir de la table temporaire deleted. Le second Trigger se déclenche et exécute ses propres instructions à la place de la commande de déclenchement DELETE afin d'effectuer une comparaison entre les noms de produit sur les deux tables tbl_produit et deleted pour ensuite supprimer les enregistrements possédant un identificateur égal à zéro.
Les deux derniers exemples démontrent qu'il est possible d'exécuter diverses instructions telles que respectivement, l'envoi d'un courrier électronique notifiant une modification à l'administrateur de la base de données et du retour d'un message d'erreur par l'instruction RAISERROR.
Un curseur SQL représente une zone de mémoire de la base de données où la dernière instruction SQL est stockée.
Syntaxe sous SQL Server
DECLARE nom_curseur [ INSENSITIVE ] [ SCROLL ] CURSOR
FOR instruction_sélection
[ FOR { READ ONLY | UPDATE [ OF nom_colonne [ ,...n ] ] } ]
Syntaxe sous Oracle
DECLARE CURSOR nom_curseur [(paramètre[, paramètre]...)]
[RETURN return_type] IS instruction_sélection;
Il est également possible de passer des paramètres à un curseur.
-- Exemple Oracle
DECLARE
employe_nom employe.eNom%TYPE;
salaire employe.eSalaire%TYPE;
CURSOR curseur1 (nom VARCHAR2, sal NUMBER)
IS SELECT e.eNum, e.eNom, e.ePoste, r.eSalaire
FROM employe AS e, remuneration AS r
WHERE e.eNom = nom AND r.eSalaire = sal;
BEGIN
OPEN curseur1('DUPONT', 3000);
LOOP
FETCH curseur1 INTO @employe, @salaire;
EXIT WHEN curseur1%NOTFOUND;
END LOOP;
END;
...
-- Exemple SQL Server
DECLARE @employe_nom VARCHAR(11), @numero INT, @salaire INT
DECLARE curseur1 CURSOR
FOR SELECT eNum, eNom FROM employe
OPEN curseur1
FETCH curseur1 INTO @numero, @employe_nom
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH curseur1 INTO @numero, @employe_nom
DECLARE curseur2 CURSOR
FOR SELECT eSalaire, eNom FROM remuneration
WHERE eNum = @numero
OPEN curseur2
FETCH NEXT FROM curseur2 INTO @salaire
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @numero + ' ' + @employe_nom + ' ' + @salaire
FETCH NEXT FROM curseur2 INTO @salaire
END
END
...
Un curseur s'ouvre par l'intermédiaire de la commande OPEN suivi du nom du curseur et de ses éventuels arguments.
OPEN nom_curseur[(liste_arguments...)];
La commande FETCH permet de parcourir un enregistrement du curseur ouvert. L'ensemble des enregistrements d'un curseur peut être parcouru à l'aide d'une structure itérative.
-- Exemple Oracle
LOOP
FETCH CurseurEmploye INTO sal;
EXIT WHEN nom_curseur%NOTFOUND;
i = i + 1;
END LOOP;
-- Exemple SQL Server
FETCH NEXT FROM nom_curseur
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM nom_curseur;
END
La fonction SQLServer @@FETCH_STATUS retourne l'état de la dernière instruction FETCH appliquée au curseur en cours d'utilisation. Les valeurs 0, -1 et -2 indiquent respectvement si l'instruction FETCH a réussi ou a échouée et si la ligne recherchée n'a pas été trouvée.
L'attribut Oracle %NOTFOUND retourne FALSE si la dernière instruction FETCH renvoie un enregistrement ou TRUE en cas d'échec.
Suite à la fin de son utilisation, le curseur peut être fermé afin de ne plus consommer de ressources. Il est également possible de désallouer le curseur.
CLOSE nom_curseur;
-- Exemple SQL Server
DESALLOCATE nom_curseur;
-- Exemple Oracle
DESALLOCATE CURSOR nom_curseur;
Exemples
-- Exemple Oracle
DECLARE
sal employe.eSalaire%TYPE;
i INTEGER := 0;
CURSOR CurseurEmploye
IS SELECT eNum, eNom, ePoste, eSalaire FROM employe
WHERE eSalaire > 1600;
BEGIN
OPEN CurseurEmploye;
LOOP
FETCH CurseurEmploye INTO sal;
EXIT WHEN CurseurEmploye%NOTFOUND;
i = i + 1;
END LOOP;
CLOSE CurseurEmploye;
DEALLOCATE CURSOR CurseurEmploye;
END;
-- Exemple SQL Server
DECLARE CURSOR CurseurEmploye FOR
SELECT eNum, eNom, ePoste, eSalaire FROM employe
WHERE eSalaire > 1600;
BEGIN
OPEN CurseurEmploye;
END
FETCH NEXT FROM CurseurEmploye
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM CurseurEmploye;
END
CLOSE CurseurEmploye;
DEALLOCATE CurseurEmploye; |