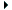| Champ | Option |
|---|
| Description |
|---|
| CANON_EQ | |
|---|
Deux caractères correspondent si et seulement si leurs décompositions canoniques correspondent (ex.: '\\u00E0' correspond à 'à'). |
| CASE_INSENSITIVE | (?i)regexp |
|---|
| Les caractères US-ASCII minuscules ou majuscules correspondent (ex.: 'A' correspond à 'a'). |
| COMMENTS | (?x)regexp |
|---|
| Les espaces blancs et les commentaires commençant par le signe dièse '#' sont ignorés (ex.: ' ' ou \"#Une ligne...\" sont ignorés). |
| DOTALL | (?s)regexp |
|---|
| Le point '.' permet de remplacer tous les caractères, y compris les caractères de fin de ligne (ex.: \".*\" correspond à \"Une ligne\nUne autre ligne\n\"). |
| LITERAL | |
|---|
| L'espression est interprétée comme une séquence de caractères littérale, c'est à dire que les méta-caractères et les séquences d'échappement ne seront pas interprétés (ex.: \"\b.*\b\" recherche les occurrences \"\b.*\b\"). |
| MULTILINE | (?m)regexp |
|---|
| Les caractères '^' et '$' indiquent respectivement un début et une fin de ligne (ex.: \"^A.*$\" correspond à \"Alors...\\n\"). |
| UNICODE_CASE | (?u)regexp |
|---|
| L'expression de recherche est insensible à la casse des caractères, y compris pour tous les caractères Unicode (ex.: \u00C0 correspond à \u00E0). |
| UNIX_LINES | (?d)regexp |
|---|
| Le terminateur de lignes correspond à un caractère de fin de ligne Unix (Line Feed : \\n). |
| Méthode |
|---|
| Description |
|---|
| static Pattern compile(String regex) |
|---|
| crée un modèle à partir de l'expression régulière fournie. |
| static Pattern compile(String regex, int flags) |
|---|
| crée un modèle à partir de l'expression régulière et d'un indicateur passés en argument. L'indicateur est une combinaison des options précitées. |
| int flags() |
|---|
| retourne l'indicateur pour le modèle courant. |
| Matcher matcher(CharSequence input) |
|---|
| crée un objet Matcher qui appliquera le modèle courant sur la chaîne de caractères passée en argument. |
| static boolean matches(String regex, CharSequence input) |
|---|
| compile une expression régulière à appliquer sur la chaîne de caractères fournie. |
| String pattern() |
|---|
| retourne l'expression régulière du modèle courant. |
| String[] split(CharSequence input) |
|---|
| découpe la chaîne de caractères spécifiée en fonction du modèle courant. |
| String[] split(CharSequence input, int limit) |
|---|
découpe la chaîne de caractères spécifiée en fonction du modèle courant. La limite indique le nombre de fois que le modèle courant devra s'appliquer à la chaîne de caractères.
- n < 0 : n-1 applications du modèle.
- n = 0 : autant d'applications que possible, mais les sous-chaînes de caractères vides sont supprimées.
- n > 0 : autant d'applications que possible en conservant toutes les sous-chaînes y-compris les vides.
|